day08-Stream流、File类
一、JDK8新特性(Stream流)
接下来我们学习一个全新的知识,叫做Stream流(也叫Stream
API)。它是从JDK8以后才有的一个新特性,是专业用于对集合或者数组进行便捷操作的。有多方便呢?我们用一个案例体验一下,然后再详细学习。
1.1 Stream流体验
案例需求:有一个List集合,元素有"张三丰","张无忌","周芷若","赵敏","张强",找出姓张,且是3个字的名字,存入到一个新集合中去。
1
2
3
| List<String> names = new ArrayList<>();
Collections.addAll(names, "张三丰","张无忌","周芷若","赵敏","张强");
System.out.println(names);
|
1
2
3
4
5
6
7
8
|
List<String> list = new ArrayList<>();
for (String name : names) {
if(name.startsWith("张") && name.length() == 3){
list.add(name);
}
}
System.out.println(list);
|
- 用Stream流来做,代码是这样的(ps:
是不是像流水线一样,一句话就写完了)
1
2
| List<String> list2 = names.stream().filter(s -> s.startsWith("张")).filter(a -> a.length()==3).collect(Collectors.toList());
System.out.println(list2);
|
先不用知道这里面每一句话是什么意思,具体每一句话的含义,待会再一步步学习。现在只是体验一下。
学习Stream流我们接下来,会按照下面的步骤来学习。
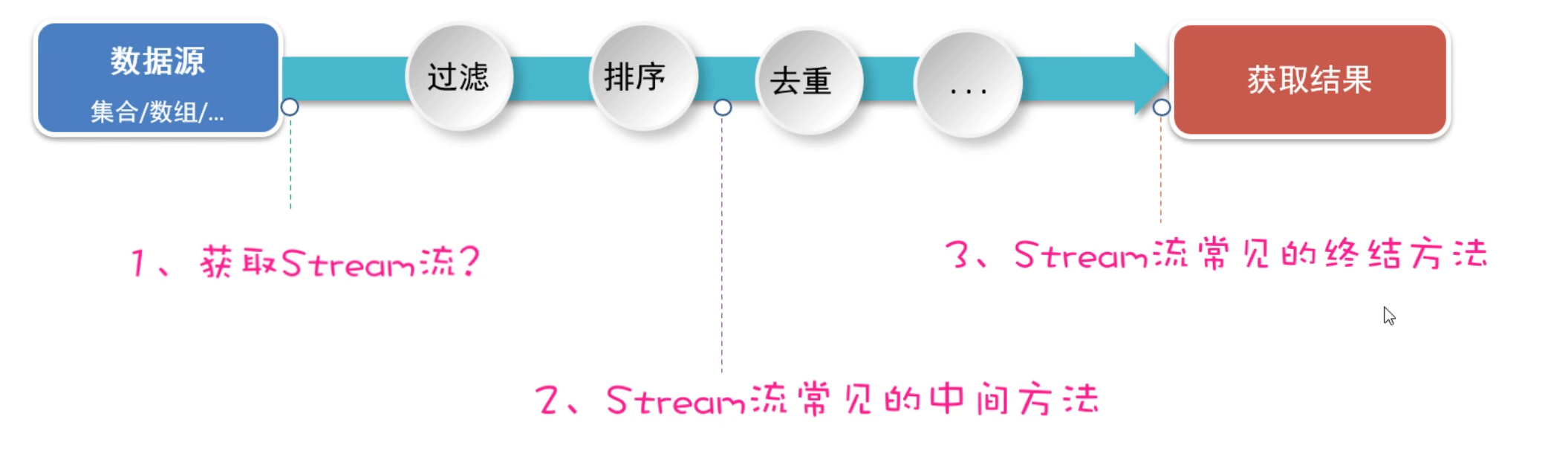
1.2 Stream流的创建
好,接下来我们正式来学习Stream流。先来学习如何创建Stream流、或者叫获取Stream流。
1
2
3
4
5
| 主要掌握下面四点:
1、如何获取List集合的Stream流?
2、如何获取Set集合的Stream流?
3、如何获取Map集合的Stream流?
4、如何获取数组的Stream流?
|
直接上代码演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public class StreamTest2 {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
Collections.addAll(names, "张三丰","张无忌","周芷若","赵敏","张强");
Stream<String> stream = names.stream();
Set<String> set = new HashSet<>();
Collections.addAll(set, "刘德华","张曼玉","蜘蛛精","马德","德玛西亚");
Stream<String> stream1 = set.stream();
stream1.filter(s -> s.contains("德")).forEach(s -> System.out.println(s));
Map<String, Double> map = new HashMap<>();
map.put("古力娜扎", 172.3);
map.put("迪丽热巴", 168.3);
map.put("马尔扎哈", 166.3);
map.put("卡尔扎巴", 168.3);
Set<String> keys = map.keySet();
Stream<String> ks = keys.stream();
Collection<Double> values = map.values();
Stream<Double> vs = values.stream();
Set<Map.Entry<String, Double>> entries = map.entrySet();
Stream<Map.Entry<String, Double>> kvs = entries.stream();
kvs.filter(e -> e.getKey().contains("巴"))
.forEach(e -> System.out.println(e.getKey()+ "-->" + e.getValue()));
String[] names2 = {"张翠山", "东方不败", "唐大山", "独孤求败"};
Stream<String> s1 = Arrays.stream(names2);
Stream<String> s2 = Stream.of(names2);
}
}
|
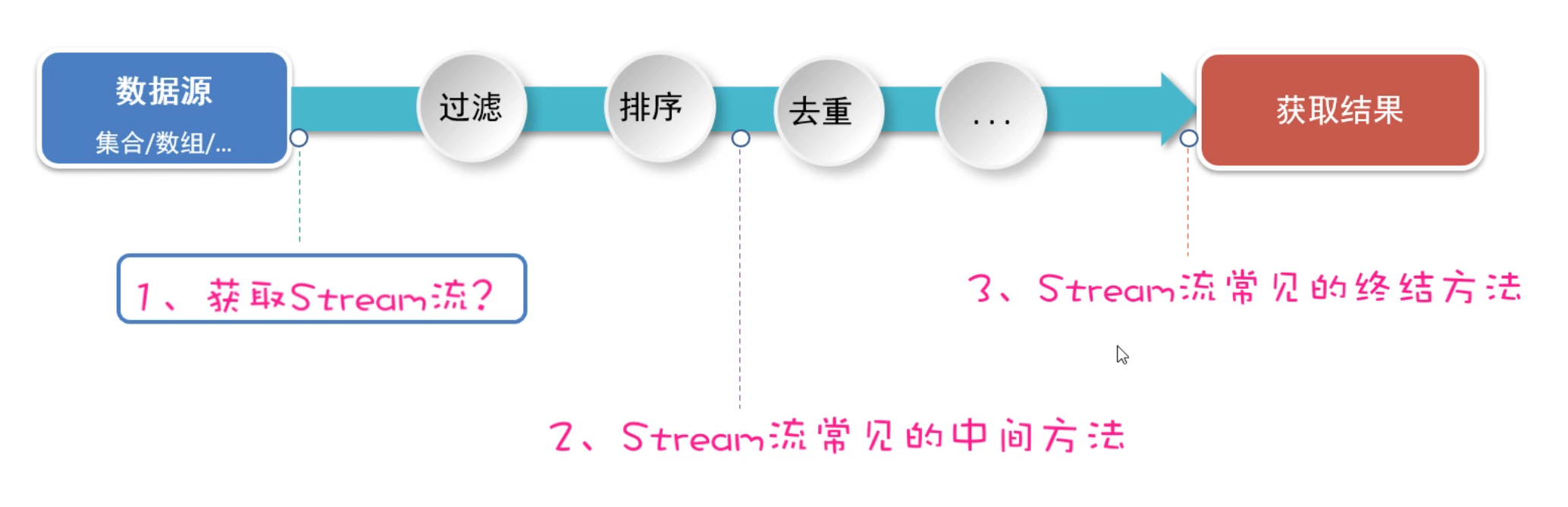
1.3 Stream流中间方法
在上一节,我们学习了创建Stream流的方法。接下来我们再来学习,Stream流中间操作的方法。
中间方法指的是:调用完方法之后其结果是一个新的Stream流,于是可以继续调用方法,这样一来就可以支持链式编程(或者叫流式编程)。
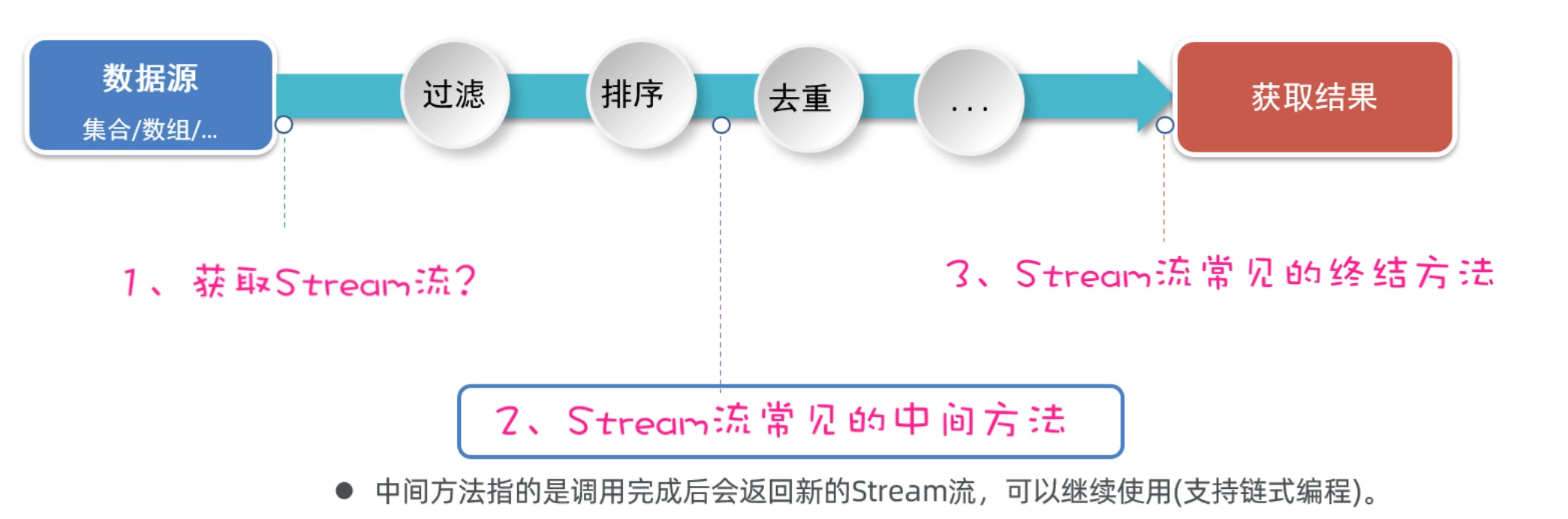

话不多说,直接上代码演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
public class StreamTest3 {
public static void main(String[] args) {
List<Double> scores = new ArrayList<>();
Collections.addAll(scores, 88.5, 100.0, 60.0, 99.0, 9.5, 99.6, 25.0);
scores.stream().filter(s -> s >= 60).sorted().forEach(s -> System.out.println(s));
List<Student> students = new ArrayList<>();
Student s1 = new Student("蜘蛛精", 26, 172.5);
Student s2 = new Student("蜘蛛精", 26, 172.5);
Student s3 = new Student("紫霞", 23, 167.6);
Student s4 = new Student("白晶晶", 25, 169.0);
Student s5 = new Student("牛魔王", 35, 183.3);
Student s6 = new Student("牛夫人", 34, 168.5);
Collections.addAll(students, s1, s2, s3, s4, s5, s6);
students.stream().filter(s -> s.getAge() >= 23 && s.getAge() <= 30)
.sorted((o1, o2) -> o2.getAge() - o1.getAge())
.forEach(s -> System.out.println(s));
students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight()))
.limit(3).forEach(System.out::println);
System.out.println("-----------------------------------------------");
students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight()))
.skip(students.size() - 2).forEach(System.out::println);
students.stream().filter(s -> s.getHeight() > 168).map(Student::getName)
.distinct().forEach(System.out::println);
students.stream().filter(s -> s.getHeight() > 168)
.distinct().forEach(System.out::println);
Stream<String> st1 = Stream.of("张三", "李四");
Stream<String> st2 = Stream.of("张三2", "李四2", "王五");
Stream<String> allSt = Stream.concat(st1, st2);
allSt.forEach(System.out::println);
}
}
|
1.4 Stream流终结方法
最后,我们再学习Stream流的终结方法。这些方法的特点是,调用完方法之后,其结果就不再是Stream流了,所以不支持链式编程。
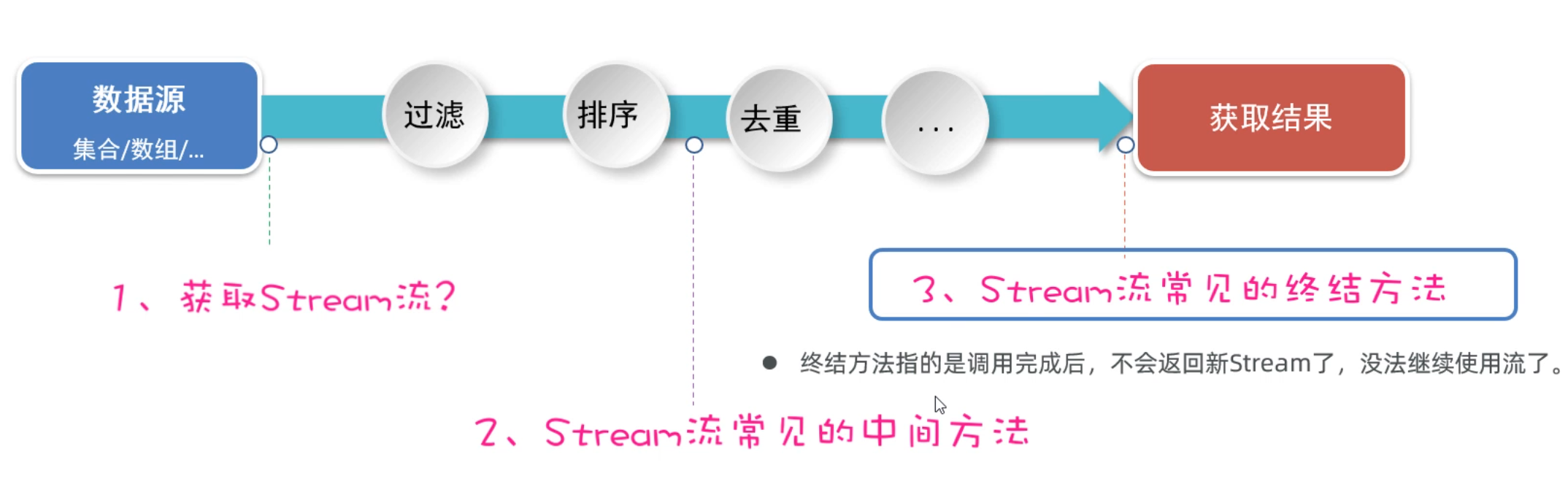
我列举了下面的几个终结方法,接下来用几个案例来一个一个给同学们演示。
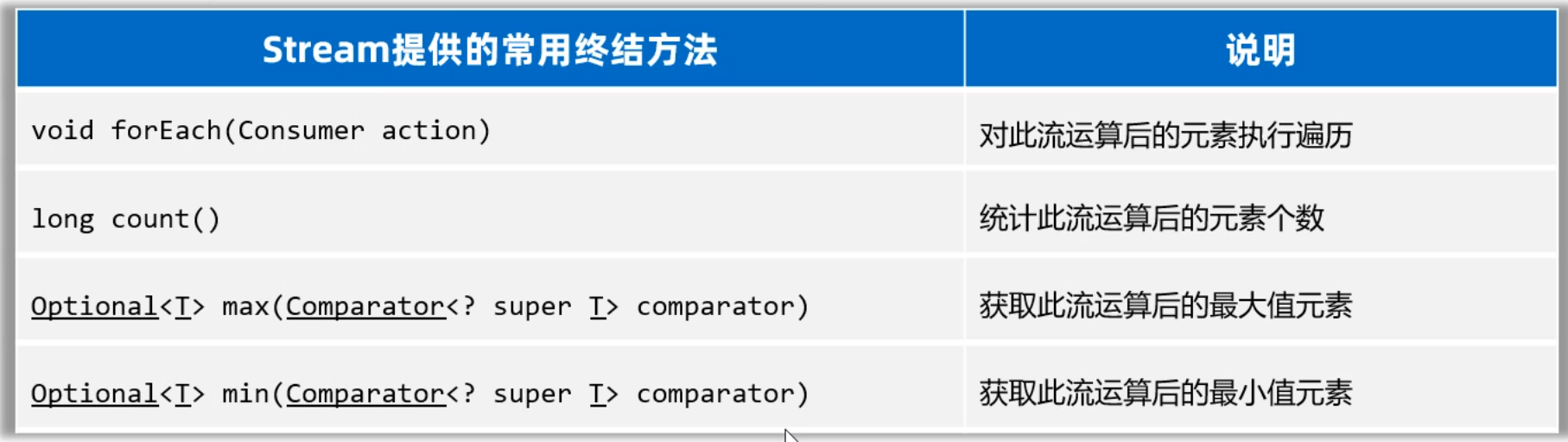
话不多说,直接上代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
public class StreamTest4 {
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
Student s1 = new Student("蜘蛛精", 26, 172.5);
Student s2 = new Student("蜘蛛精", 26, 172.5);
Student s3 = new Student("紫霞", 23, 167.6);
Student s4 = new Student("白晶晶", 25, 169.0);
Student s5 = new Student("牛魔王", 35, 183.3);
Student s6 = new Student("牛夫人", 34, 168.5);
Collections.addAll(students, s1, s2, s3, s4, s5, s6);
long size = students.stream().filter(s -> s.getHeight() > 168).count();
System.out.println(size);
Student s = students.stream().max((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get();
System.out.println(s);
Student ss = students.stream().min((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get();
System.out.println(ss);
List<Student> students1 = students.stream().filter(a -> a.getHeight() > 170).collect(Collectors.toList());
System.out.println(students1);
Set<Student> students2 = students.stream().filter(a -> a.getHeight() > 170).collect(Collectors.toSet());
System.out.println(students2);
Map<String, Double> map =
students.stream().filter(a -> a.getHeight() > 170)
.distinct().collect(Collectors.toMap(a -> a.getName(), a -> a.getHeight()));
System.out.println(map);
Student[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray(len -> new Student[len]);
System.out.println(Arrays.toString(arr));
}
}
|
到这里,关于Stream流的操常见操作我们就已经学习完了。当然Stream流还有一些其他的方法,同学们遇到了也可以自己再研究一下。
二、File类
接下来,我们要学习的知识是一个File类。但是在讲这个知识点之前,我想先和同学们聊点别的,聊完之后再回过来学习File你会更容易理解一些。
而现在要学习的File类,它的就用来表示当前系统下的文件(也可以是文件夹),通过File类提供的方法可以获取文件大小、判断文件是否存在、创建文件、创建文件夹等。

但是需要我们注意:File对象只能对文件进行操作,不能操作文件中的内容。
2.1 File对象的创建
学习File类和其他类一样,第一步是创建File类的对象。
想要创建对象,我们得看File类有哪些构造方法。
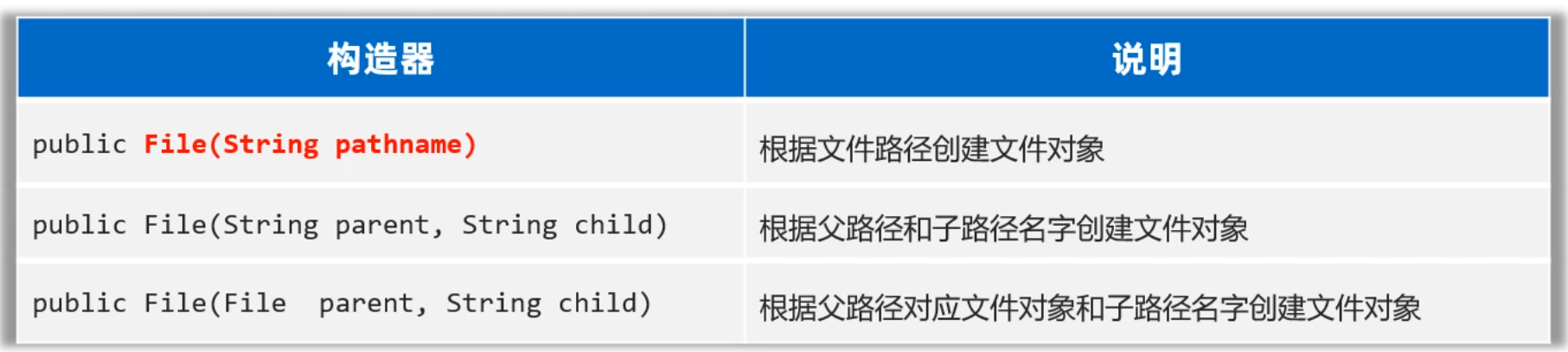
下面我们演示一下,File类创建对象的代码
1
| 需求我们注意的是:路径中"\"要写成"\\", 路径中"/"可以直接用
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public class FileTest1 {
public static void main(String[] args) {
File f1 = new File("D:" + File.separator +"resource" + File.separator + "ab.txt");
System.out.println(f1.length());
File f2 = new File("D:/resource");
System.out.println(f2.length());
File f3 = new File("D:/resource/aaaa.txt");
System.out.println(f3.length());
System.out.println(f3.exists());
File f4 = new File("file-io-app\\src\\itheima.txt");
System.out.println(f4.length());
}
}
|
2.2 File判断和获取方法
各位同学,刚才我们创建File对象的时候,会传递一个文件路径过来。但是File对象封装的路径是存在还是不存在,是文件还是文件夹其实是不清楚的。好在File类提供了方法可以帮我们做判断。
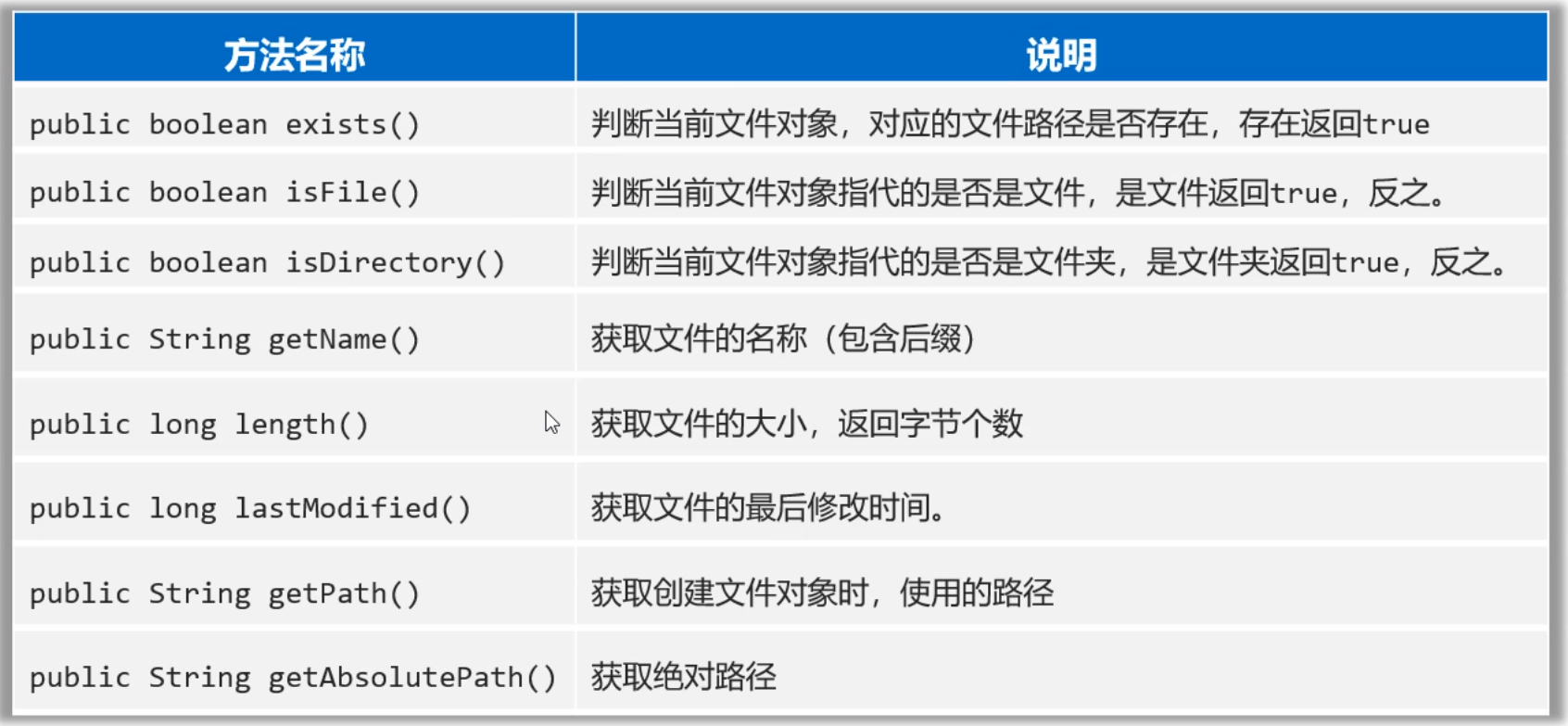
话不多少,直接上代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public class FileTest2 {
public static void main(String[] args) throws UnsupportedEncodingException {
File f1 = new File("D:/resource/ab.txt");
System.out.println(f1.exists());
System.out.println(f1.isFile());
System.out.println(f1.isDirectory());
}
}
|
除了判断功能还有一些获取功能,看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| File f1 = new File("D:/resource/ab.txt");
System.out.println(f1.getName());
System.out.println(f1.length());
long time = f1.lastModified();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
System.out.println(sdf.format(time));
File f2 = new File("D:\\resource\\ab.txt");
File f3 = new File("file-io-app\\src\\itheima.txt");
System.out.println(f2.getPath());
System.out.println(f3.getPath());
System.out.println(f2.getAbsolutePath());
System.out.println(f3.getAbsolutePath());
|
2.3 创建和删除方法
刚才有同学问老师,我们不能不用Java代码创建一个文件或者文件夹呀?答案是有的,不光可以创建还可以删除。
File类提供了创建和删除文件的方法,话不多少,看代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public class FileTest3 {
public static void main(String[] args) throws Exception {
File f1 = new File("D:/resource/itheima2.txt");
System.out.println(f1.createNewFile());
File f2 = new File("D:/resource/aaa");
System.out.println(f2.mkdir());
File f3 = new File("D:/resource/bbb/ccc/ddd/eee/fff/ggg");
System.out.println(f3.mkdirs());
System.out.println(f1.delete());
System.out.println(f2.delete());
File f4 = new File("D:/resource");
System.out.println(f4.delete());
}
}
|
需要注意的是:
1
2
3
| 1.mkdir(): 只能创建单级文件夹、
2.mkdirs(): 才能创建多级文件夹
3.delete(): 文件可以直接删除,但是文件夹只能删除空的文件夹,文件夹有内容删除不了。
|
2.4 遍历文件夹方法
有人说,想获取到一个文件夹中的内容,有没有方法呀?也是有的,下面我们就学习两个这样的方法。

话不多少上代码,演示一下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public class FileTest4 {
public static void main(String[] args) {
File f1 = new File("D:\\course\\待研发内容");
String[] names = f1.list();
for (String name : names) {
System.out.println(name);
}
File[] files = f1.listFiles();
for (File file : files) {
System.out.println(file.getAbsolutePath());
}
File f = new File("D:/resource/aaa");
File[] files1 = f.listFiles();
System.out.println(Arrays.toString(files1));
}
}
|
这里需要注意几个问题
1
2
3
4
5
| 1.当主调是文件时,或者路径不存在时,返回null
2.当主调是空文件夹时,返回一个长度为0的数组
3.当主调是一个有内容的文件夹时,将里面所有一级文件和文件夹路径放在File数组中,并把数组返回
4.当主调是一个文件夹,且里面有隐藏文件时,将里面所有文件和文件夹的路径放在FIle数组中,包含隐藏文件
5.当主调是一个文件夹,但是没有权限访问时,返回null
|
关于遍历文件夹的基本操作就学习完了。
但是有同学如果想要获取文件夹中子文件夹的内容,那目前还做不到。但是学习下面了下面的递归知识就,很容易做到了。
三、递归
各位同学,为了获取文件夹中子文件夹的内容,我们就需要学习递归这个知识点。但是递归是什么意思,我们需要单独讲一下。学习完递归是什么,以及递归的执行流程之后,我们再回过头来用递归来找文件夹中子文件夹的内容。
3.1 递归算法引入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class RecursionTest1 {
public static void main(String[] args) {
test1();
}
public static void test1(){
System.out.println("----test1---");
test1();
}
public static void test2(){
System.out.println("---test2---");
test3();
}
public static void test3(){
test2();
}
}
|
如果直接执行上面的代码,会进入死循环,最终导致栈内存溢出

以上只是用代码演示了一下,递归的形式。在下一节,在通过一个案例来给同学们讲一讲递归的执行流程。
3.2 递归算法的执行流程
为了弄清楚递归的执行流程,接下来我们通过一个案例来学习一下。
案例需求:计算n的阶乘,比如5的阶乘 = 1 * 2 * 3 * 4 * 5 ; 6 的阶乘 =
1 * 2 * 3 * 4 * 5 * 6
分析需求用递归该怎么做
1
2
3
4
5
6
7
8
9
10
| 假设f(n)表示n的阶乘,那么我们可以推导出下面的式子
f(5) = 1+2+3+4+5
f(5) = f(4)+5
f(4) = f(3)+4
f(3) = f(2)+3
f(2) = f(1)+2
f(1) = 1
总结规律:
除了f(1) = 1; 出口
其他的f(n) = f(n-1)+n
|
我们可以把f(n)当做一个方法,那么方法的写法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public class RecursionTest2 {
public static void main(String[] args) {
System.out.println("5的阶乘是:" + f(5));
}
public static int f(int n){
if(n == 1){
return 1;
}else {
return f(n - 1) * n;
}
}
}
|
这个代码的执行流程,我们用内存图的形式来分析一下,该案例中递归调用的特点是:一层一层调用,再一层一层往回返。
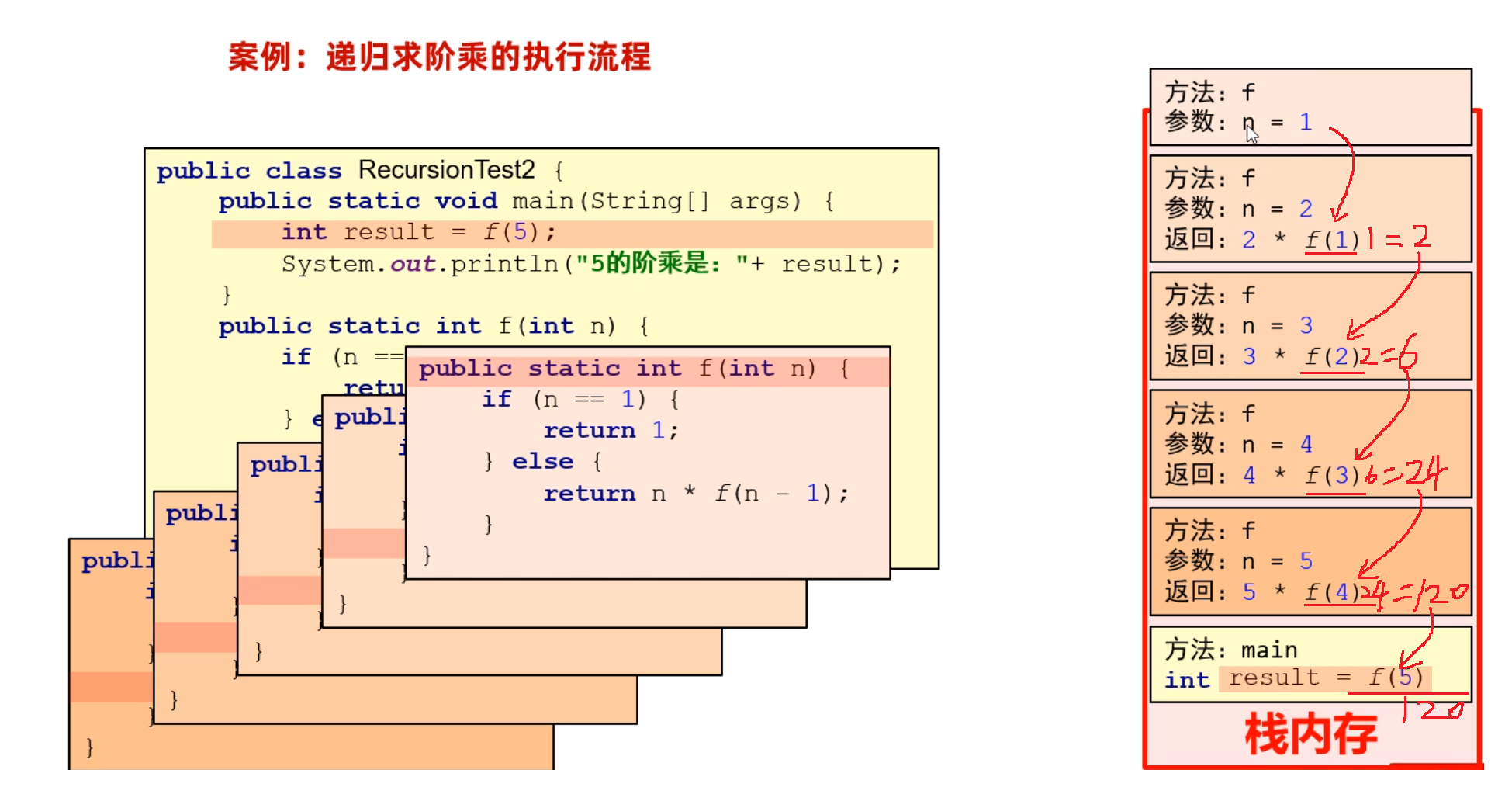
3.3 递归文件搜索
学习完递归算法执行流程后,最后我们回过头来。再来看一下,如果使用递归来遍历文件夹。
案例需求:在D:\\判断下搜索QQ.exe这个文件,然后直接输出。
1
2
3
4
5
6
| 1.先调用文件夹的listFiles方法,获取文件夹的一级内容,得到一个数组
2.然后再遍历数组,获取数组中的File对象
3.因为File对象可能是文件也可能是文件夹,所以接下来就需要判断
判断File对象如果是文件,就获取文件名,如果文件名是`QQ.exe`则打印,否则不打印
判断File对象如果是文件夹,就递归执行1,2,3步骤
所以:把1,2,3步骤写成方法,递归调用即可。
|
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
public class RecursionTest3 {
public static void main(String[] args) throws Exception {
searchFile(new File("D:/") , "QQ.exe");
}
public static void searchFile(File dir, String fileName) throws Exception {
if(dir == null || !dir.exists() || dir.isFile()){
return;
}
File[] files = dir.listFiles();
if(files != null && files.length > 0){
for (File f : files) {
if(f.isFile()){
if(f.getName().contains(fileName)){
System.out.println("找到了:" + f.getAbsolutePath());
Runtime runtime = Runtime.getRuntime();
runtime.exec(f.getAbsolutePath());
}
}else {
searchFile(f, fileName);
}
}
}
}
}
|
day09-字符集、IO流(一)
各位同学,前面我们已经学习了File类,通过File类的对象可以对文件进行操作,但是不能操作文件中的内容。要想操作文件中的内容,我们还得学习IO流。但是在正式学习IO流之前,我们还需要学习一个前置知识叫做字符集,只有我们把字符集搞明白了,再学习IO流才会更加丝滑。
一、字符集
1.1 字符集的来历
所以,接下来我们正式学习一下字符集。先来带着同学们,了解一下字符集的来历。
我们知道计算机是美国人发明的,由于计算机能够处理的数据只能是0和1组成的二进制数据,为了让计算机能够处理字符,于是美国人就把他们会用到的每一个字符进行了编码(所谓编码,就是为一个字符编一个二进制数据),如下图所示:

美国人常用的字符有英文字母、标点符号、数字以及一些特殊字符,这些字符一共也不到128个,所以他们用1个字节来存储1字符就够了。
美国人把他们用到的字符和字符对应的编码总结成了一张码表,这张码表叫做ASCII码表(也叫ASCII字符集)。
其实计算机只在美国用是没有问题的,但是计算机慢慢的普及到全世界,当普及到中国的时候,在计算机中想要存储中文,那ASCII字符集就不够用了,因为中文太多了,随便数一数也有几万个字符。
于是中国人为了在计算机中存储中文,也编了一个中国人用的字符集叫做GBK字符集,这里面包含2万多个汉字字符,GBK中一个汉字采用两个字节来存储,为了能够显示英文字母,GBK字符集也兼容了ASCII字符集,在GBK字符集中一个字母还是采用一个字节来存储。
1.2 汉字和字母的编码特点
讲到这里,可能有同学有这么一个疑问:
如果一个文件中既有中文,也有英文,那计算机怎么知道哪几个字节表示一个汉字,哪几个字节表示一个字母呢?
其实这个问题问当想当有水平,接下来,就带着同学们了解一下,计算机是怎么识别中文和英文的。
比如:在文件中存储一个我a你,底层其实存储的是这样的二进制数据。
需要我们注意汉字和字母的编码特点:
- 如果是存储字母,采用1个字节来存储,一共8位,其中第1位是0
- 如果是存储汉字,采用2个字节来存储,一共16位,其中第1位是1

当读取文件中的字符时,通过识别读取到的第1位是0还是1来判断是字母还是汉字
- 如果读取到第1位是0,就认为是一个字母,此时往后读1个字节。
- 如果读取到第1位是1,就认为是一个汉字,此时往后读2个字节。
1.3 Unicode字符集
同学们注意了,咱们国家可以用GBK字符集来表示中国人使用的文字,那世界上还有很多其他的国家,他们也有自己的文字,他们也想要自己国家的文字在计算机中处理,于是其他国家也在搞自己的字符集,就这样全世界搞了上百个字符集,而且各个国家的字符集互不兼容。
这样其实很不利于国际化的交流,可能一个文件在我们国家的电脑上打开好好的,但是在其他国家打开就是乱码了。
为了解决各个国家字符集互不兼容的问题,由国际化标准组织牵头,设计了一套全世界通用的字符集,叫做Unicode字符集。在Unicode字符集中包含了世界上所有国家的文字,一个字符采用4个自己才存储。
在Unicode字符集中,采用一个字符4个字节的编码方案,又造成另一个问题:如果是说英语的国家,他们只需要用到26大小写字母,加上一些标点符号就够了,本身一个字节就可以表示完,用4个字节就有点浪费。
于是又对Unicode字符集中的字符进行了重新编码,一共设计了三种编码方案。分别是UTF-32、UTF-16、UTF-8;
其中比较常用的编码方案是UTF-8
下面我们详细介绍一下UTF-8这种编码方案的特点。
1
2
3
4
| 1.UTF-8是一种可变长的编码方案,工分为4个长度区
2.英文字母、数字占1个字节兼容(ASCII编码)
3.汉字字符占3个字节
4.极少数字符占4个字节
|
1.4 字符集小结
最后,我们将前面介绍过的字符集小结一下
1
2
3
4
5
6
7
8
| ASCII字符集:《美国信息交换标准代码》,包含英文字母、数字、标点符号、控制字符
特点:1个字符占1个字节
GBK字符集:中国人自己的字符集,兼容ASCII字符集,还包含2万多个汉字
特点:1个字母占用1个字节;1个汉字占用2个字节
Unicode字符集:包含世界上所有国家的文字,有三种编码方案,最常用的是UTF-8
UTF-8编码方案:英文字母、数字占1个字节兼容(ASCII编码)、汉字字符占3个字节
|
1.5 编码和解码
搞清楚字符集的知识之后,我们接下来再带着同学们使用Java代码完成编码和解码的操作。
其实String类类中就提供了相应的方法,可以完成编码和解码的操作。
- 编码:把字符串按照指定的字符集转换为字节数组
- 解码:把字节数组按照指定的字符集转换为字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class Test {
public static void main(String[] args) throws Exception {
String data = "a我b";
byte[] bytes = data.getBytes();
System.out.println(Arrays.toString(bytes));
byte[] bytes1 = data.getBytes("GBK");
System.out.println(Arrays.toString(bytes1));
String s1 = new String(bytes);
System.out.println(s1);
String s2 = new String(bytes1, "GBK");
System.out.println(s2);
}
}
|
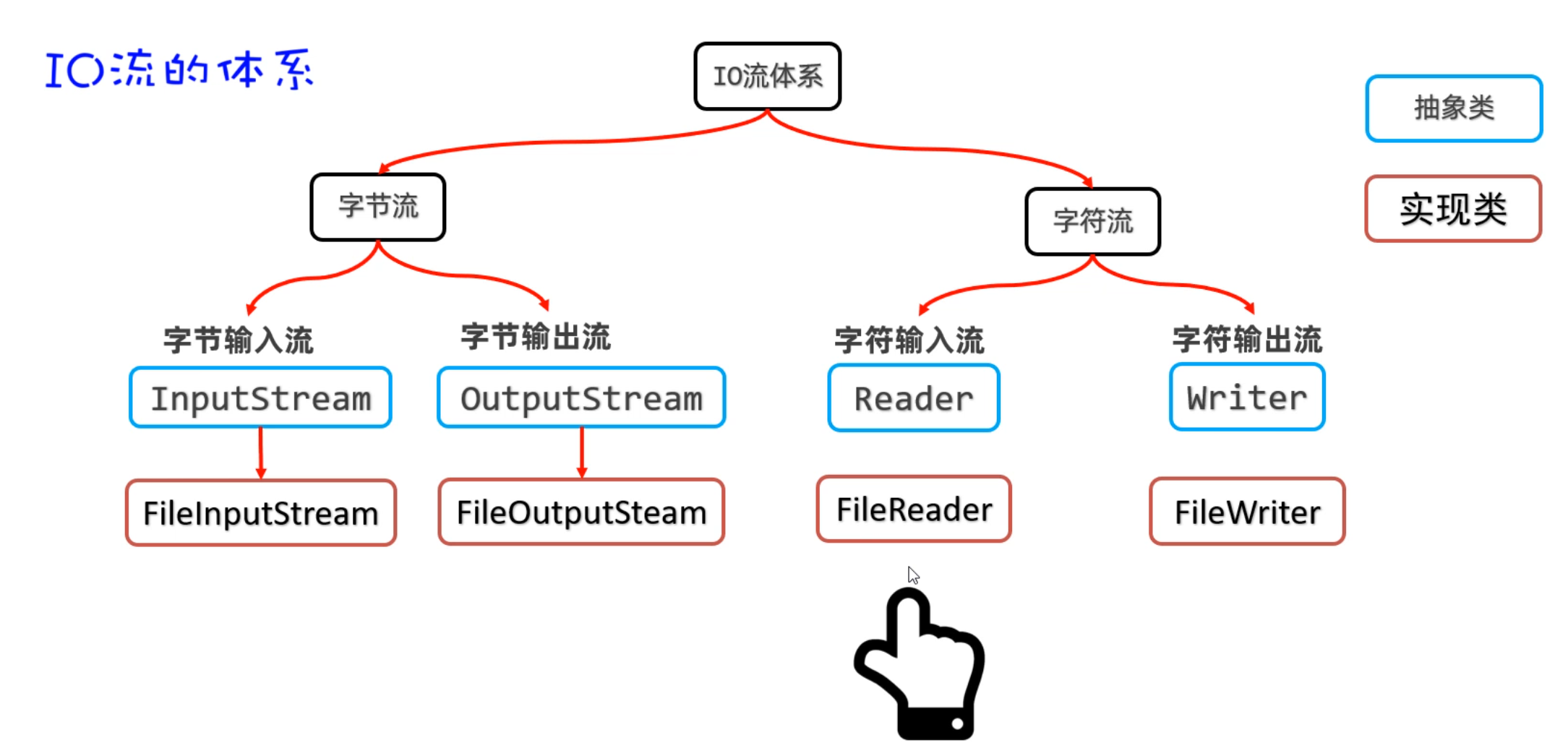
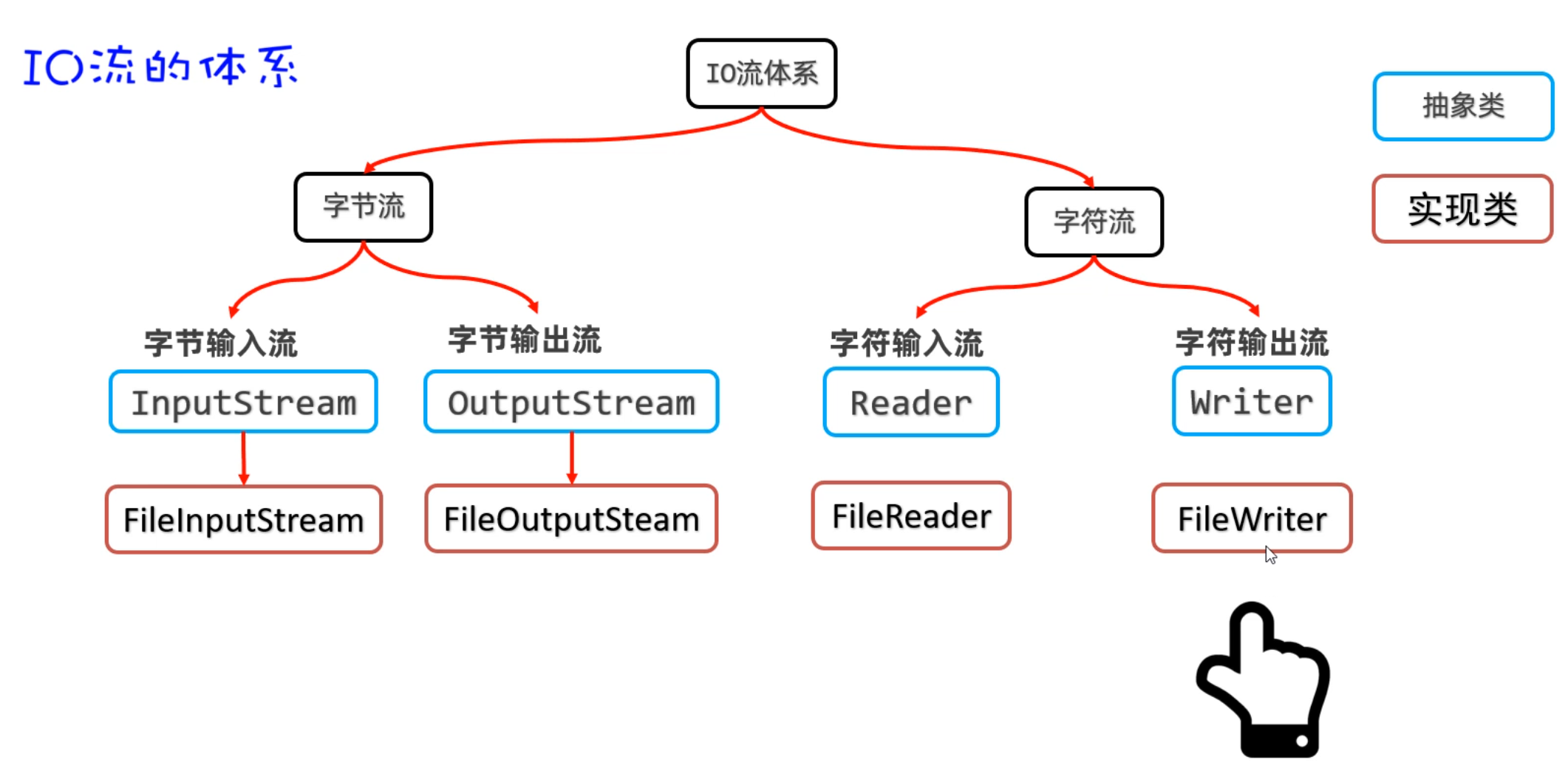
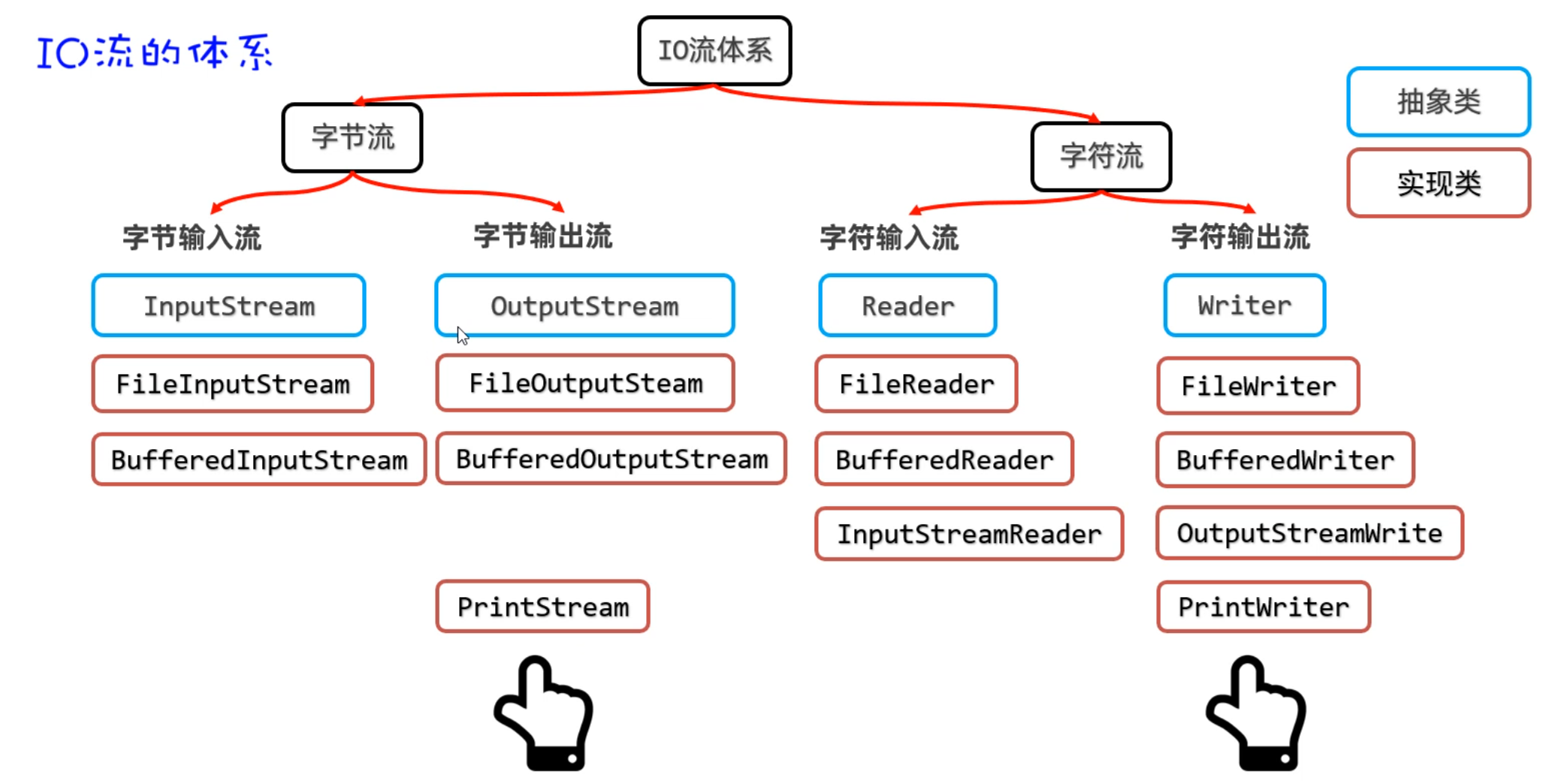
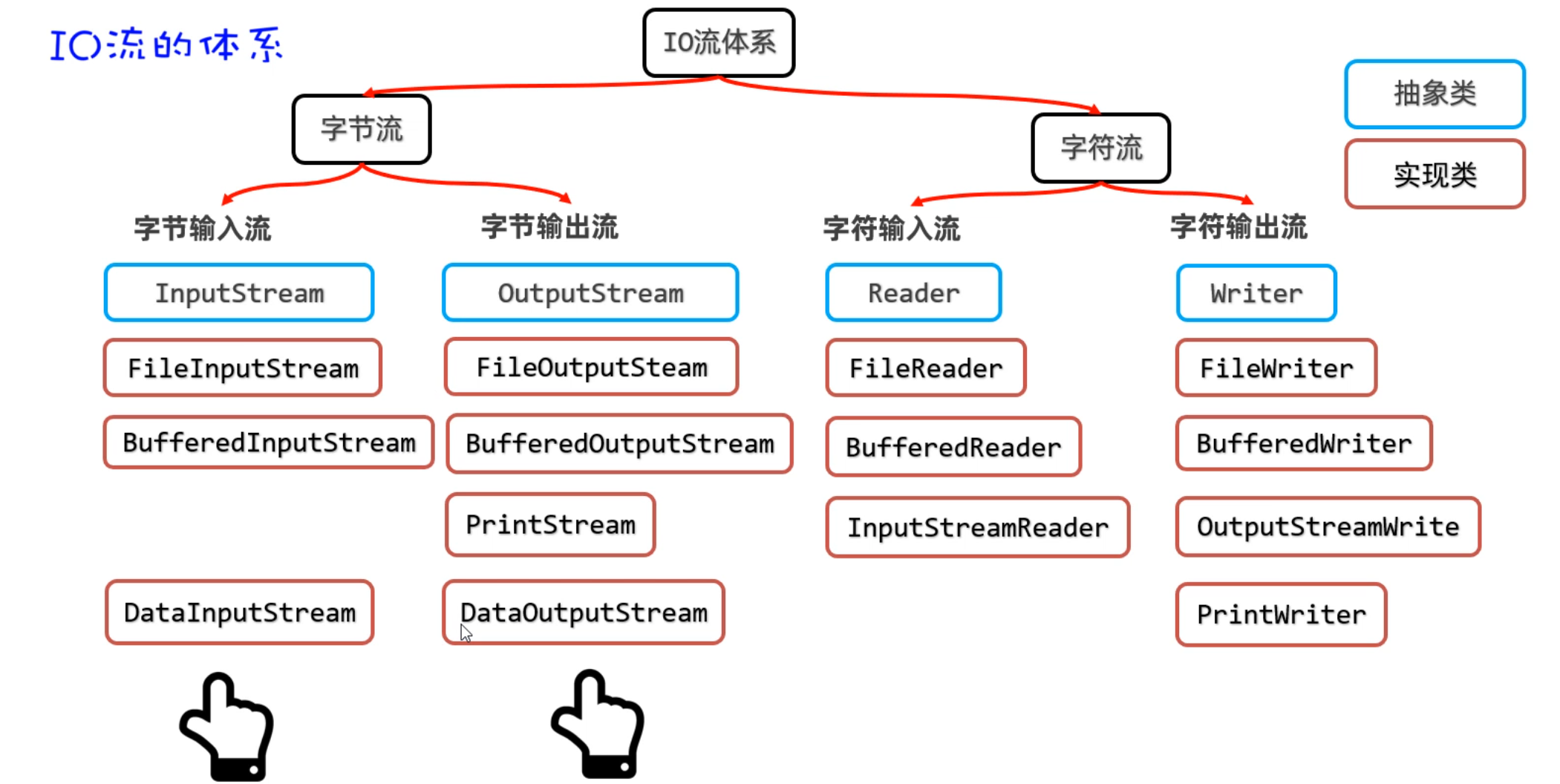
二、IO流(字节流)
2.1 IO流概述
各位小伙伴,在前面我们已经学习过File类。但是我们知道File只能操作文件,但是不能操作文件中的内容。我们也学习了字符集,不同的字符集存字符数据的原理是不一样的。有了前面两个知识的基础,接下来我们再学习IO流,就可以对文件中的数据进行操作了。
IO流的作用:就是可以对文件或者网络中的数据进行读、写的操作。如下图所示
- 把数据从磁盘、网络中读取到程序中来,用到的是输入流。
- 把程序中的数据写入磁盘、网络中,用到的是输出流。
- 简单记:输入流(读数据)、输出流(写数据)

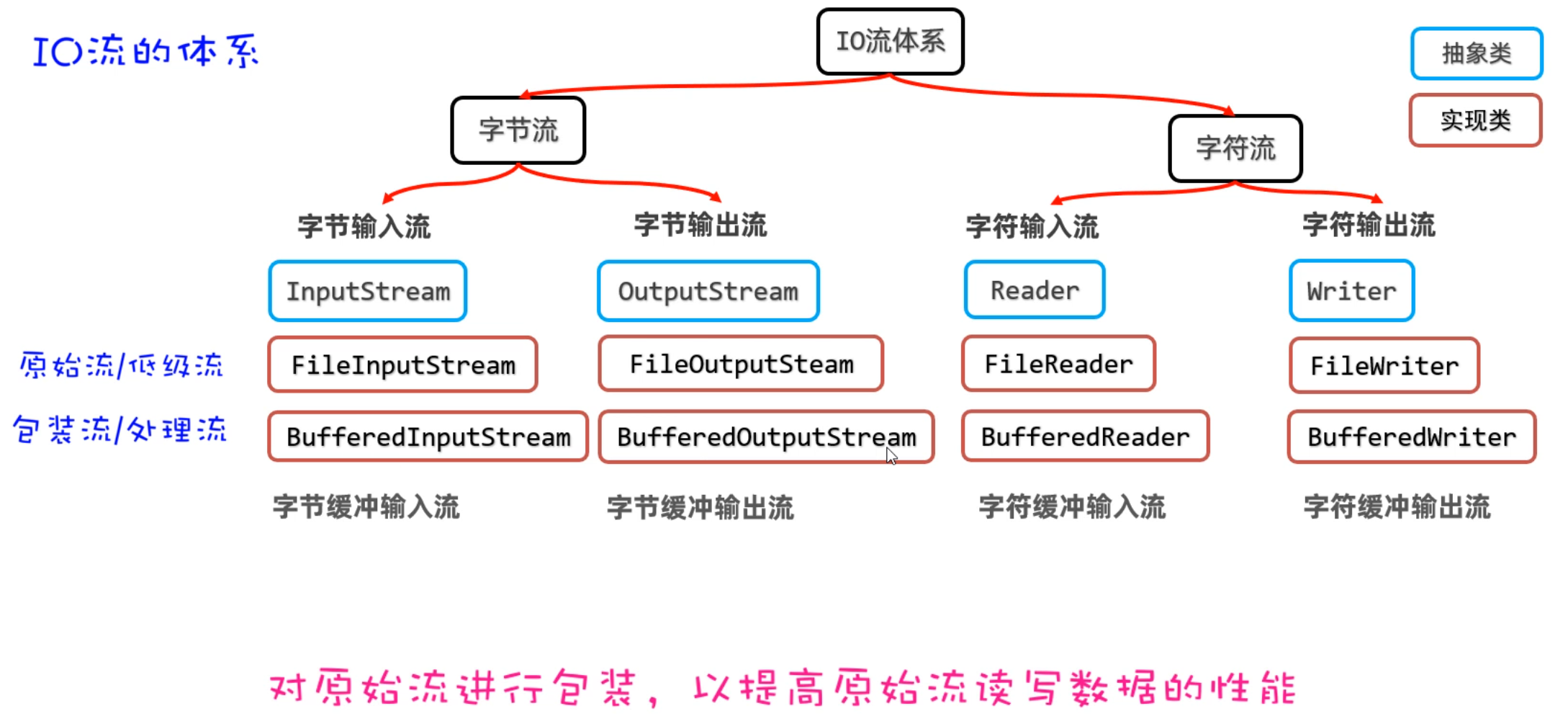
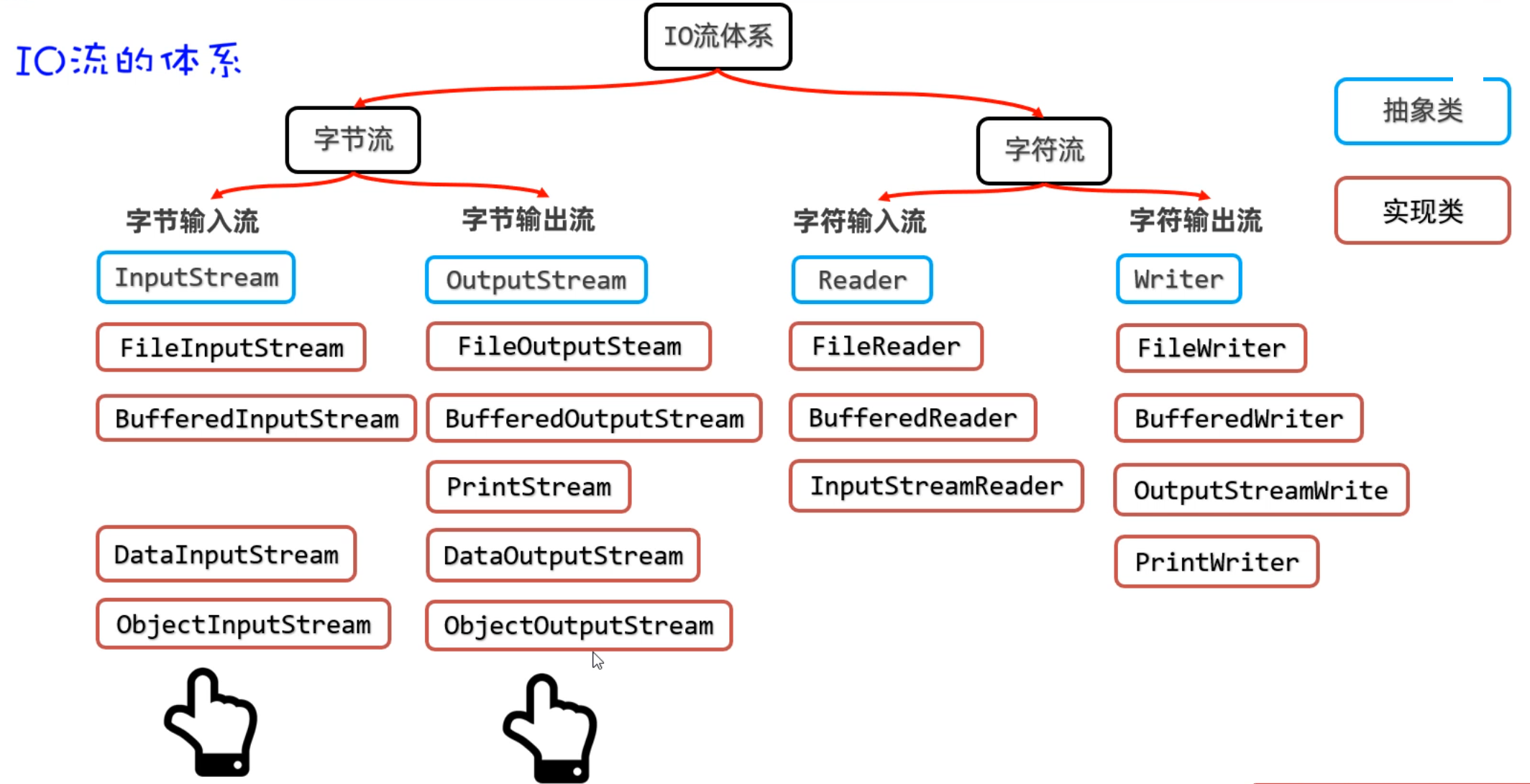
IO流在Java中有很多种,不同的流来干不同的事情。Java把各种流用不同的类来表示,这些流的继承体系如下图所示:
1
2
3
| IO流分为两大派系:
1.字节流:字节流又分为字节输入流、字节输出流
2.字符流:字符流由分为字符输入流、字符输出流
|
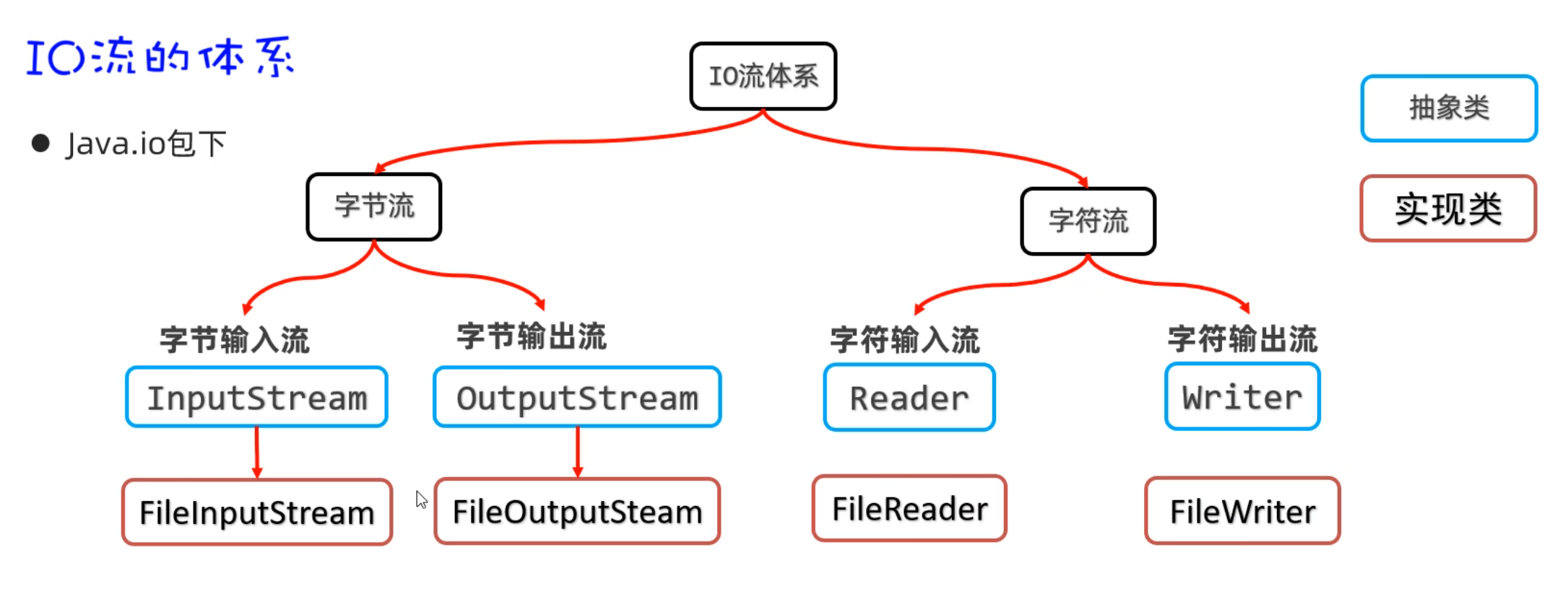
同学们,在上节课认识了什么是IO流,接下来我们学习字节流中的字节输入流,用InputStream来表示。但是InputStream是抽象类,我们用的是它的子类,叫FileInputStream。
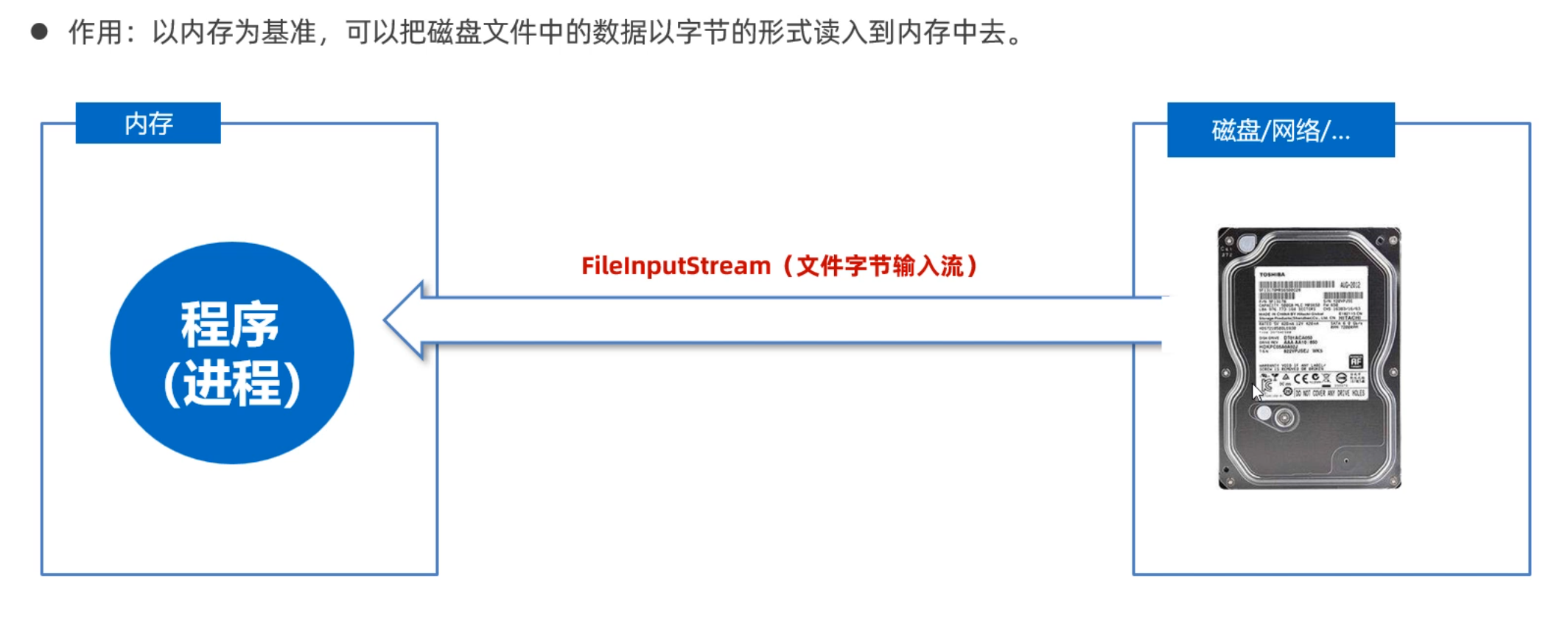
需要用到的方法如下图所示:有构造方法、成员方法

使用FileInputStream读取文件中的字节数据,步骤如下
1
2
3
| 第一步:创建FileInputStream文件字节输入流管道,与源文件接通。
第二步:调用read()方法开始读取文件的字节数据。
第三步:调用close()方法释放资源
|
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public class FileInputStreamTest1 {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream(("file-io-app\\src\\itheima01.txt"));
int b;
while ((b = is.read()) != -1){
System.out.print((char) b);
}
is.close();
}
}
|
这里需要注意一个问题:由于一个中文在UTF-8编码方案中是占3个字节,采用一次读取一个字节的方式,读一个字节就相当于读了1/3个汉字,此时将这个字节转换为字符,是会有乱码的。
各位同学,在上一节我们学习了FileInputStream调用read()方法,可以一次读取一个字节。但是这种读取方式效率太太太太慢了。
为了提高效率,我们可以使用另一个read(byte[]
bytes)的重载方法,可以一次读取多个字节,至于一次读多少个字节,就在于你传递的数组有多大。
使用FileInputStream一次读取多个字节的步骤如下
1
2
3
| 第一步:创建FileInputStream文件字节输入流管道,与源文件接通。
第二步:调用read(byte[] bytes)方法开始读取文件的字节数据。
第三步:调用close()方法释放资源
|
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class FileInputStreamTest2 {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream("file-io-app\\src\\itheima02.txt");
byte[] buffer = new byte[3];
int len;
while ((len = is.read(buffer)) != -1){
String rs = new String(buffer, 0 , len);
System.out.print(rs);
}
is.close();
}
}
|
- 需要我们注意的是:read(byte[]
bytes)它的返回值,表示当前这一次读取的字节个数。
假设有一个a.txt文件如下:
每次读取过程如下
1
2
3
4
| 也就是说,并不是每次读取的时候都把数组装满,比如数组是 byte[] bytes = new byte[3];
第一次调用read(bytes)读取了3个字节(分别是97,98,99),并且往数组中存,此时返回值就是3
第二次调用read(bytes)读取了2个字节(分别是99,100),并且往数组中存,此时返回值是2
第三次调用read(bytes)文件中后面已经没有数据了,此时返回值为-1
|
- 还需要注意一个问题:采用一次读取多个字节的方式,也是可能有乱码的。因为也有可能读取到半个汉字的情况。
同学们,前面我们到的读取方式,不管是一次读取一个字节,还是一次读取多个字节,都有可能有乱码。那么接下来我们介绍一种,不出现乱码的读取方式。
我们可以一次性读取文件中的全部字节,然后把全部字节转换为一个字符串,就不会有乱码了。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
InputStream is = new FileInputStream("file-io-app\\src\\itheima03.txt");
File f = new File("file-io-app\\src\\itheima03.txt");
long size = f.length();
byte[] buffer = new byte[(int) size];
int len = is.read(buffer);
System.out.println(new String(buffer));
is.close();
|

1
2
3
4
5
6
7
8
9
10
|
InputStream is = new FileInputStream("file-io-app\\src\\itheima03.txt");
byte[] buffer = is.readAllBytes();
System.out.println(new String(buffer));
is.close();
|
最后,还是要注意一个问题:一次读取所有字节虽然可以解决乱码问题,但是文件不能过大,如果文件过大,可能导致内存溢出。
2.5 FileOutputStream写字节
各位同学,前面我们学习了使用FIleInputStream读取文件中的字节数据。然后有同学就迫不及待的想学习往文件中写入数据了。
往文件中写数据需要用到OutputStream下面的一个子类FileOutputStream。写输入的流程如下图所示
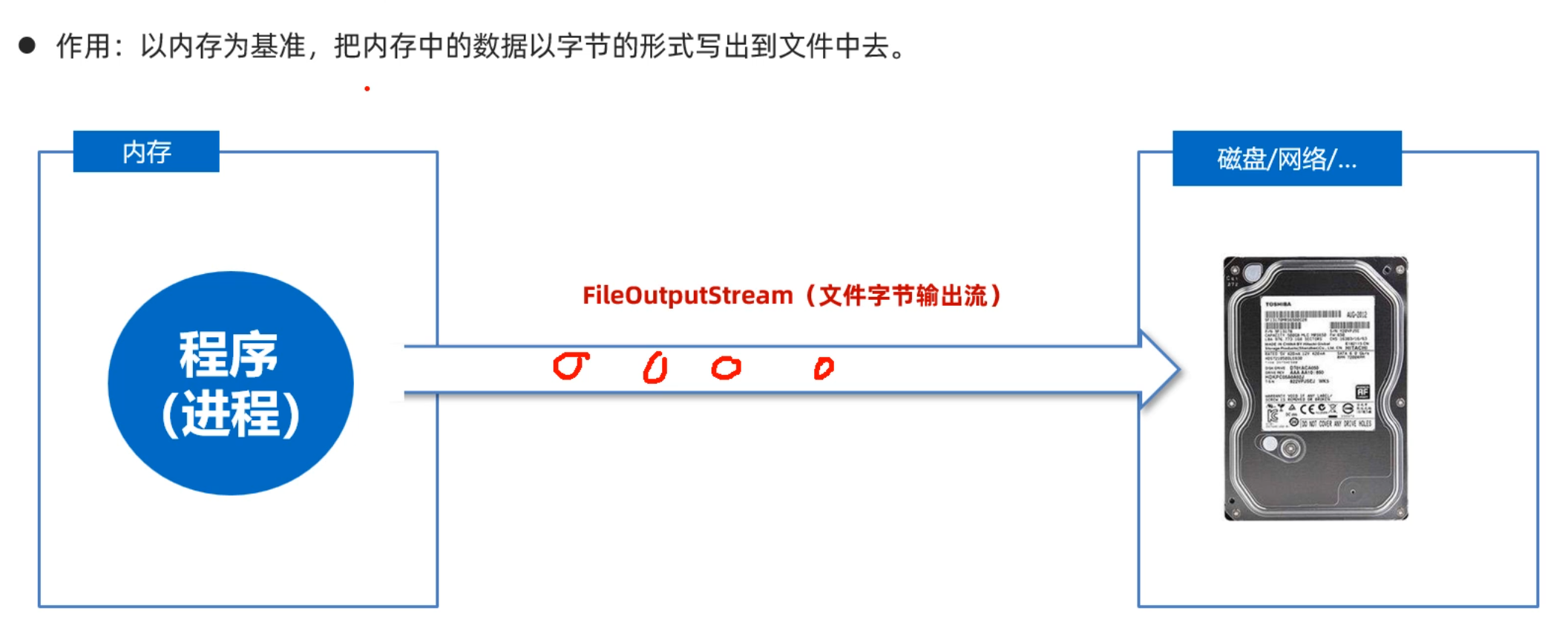
使用FileOutputStream往文件中写数据的步骤如下:
1
2
3
| 第一步:创建FileOutputStream文件字节输出流管道,与目标文件接通。
第二步:调用wirte()方法往文件中写数据
第三步:调用close()方法释放资源
|
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public class FileOutputStreamTest4 {
public static void main(String[] args) throws Exception {
OutputStream os =
new FileOutputStream("file-io-app/src/itheima04out.txt", true);
os.write(97);
os.write('b');
byte[] bytes = "我爱你中国abc".getBytes();
os.write(bytes);
os.write(bytes, 0, 15);
os.write("\r\n".getBytes());
os.close();
}
}
|
2.6 字节流复制文件
同学们,我们在前面已经把字节输入流和字节输出流都学习完了。现在我们就可以用这两种流配合起来使用,做一个文件复制的综合案例。
比如:我们要复制一张图片,从磁盘D:/resource/meinv.png的一个位置,复制到C:/data/meinv.png位置。
复制文件的思路如下图所示:
1
2
3
| 1.需要创建一个FileInputStream流与源文件接通,创建FileOutputStream与目标文件接通
2.然后创建一个数组,使用FileInputStream每次读取一个字节数组的数据,存如数组中
3.然后再使用FileOutputStream把字节数组中的有效元素,写入到目标文件中
|

代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class CopyTest5 {
public static void main(String[] args) throws Exception {
InputStream is = new FileInputStream("D:/resource/meinv.png");
OutputStream os = new FileOutputStream("C:/data/meinv.png");
System.out.println(10 / 0);
byte[] buffer = new byte[1024];
int len;
while ((len = is.read(buffer)) != -1){
os.write(buffer, 0, len);
}
os.close();
is.close();
System.out.println("复制完成!!");
}
}
|
三、IO流资源释放
各位同学,前面我们已经学习了字节流,也给同学们强调过,流使用完之后一定要释放资源。但是我们之前的代码并不是很专业。
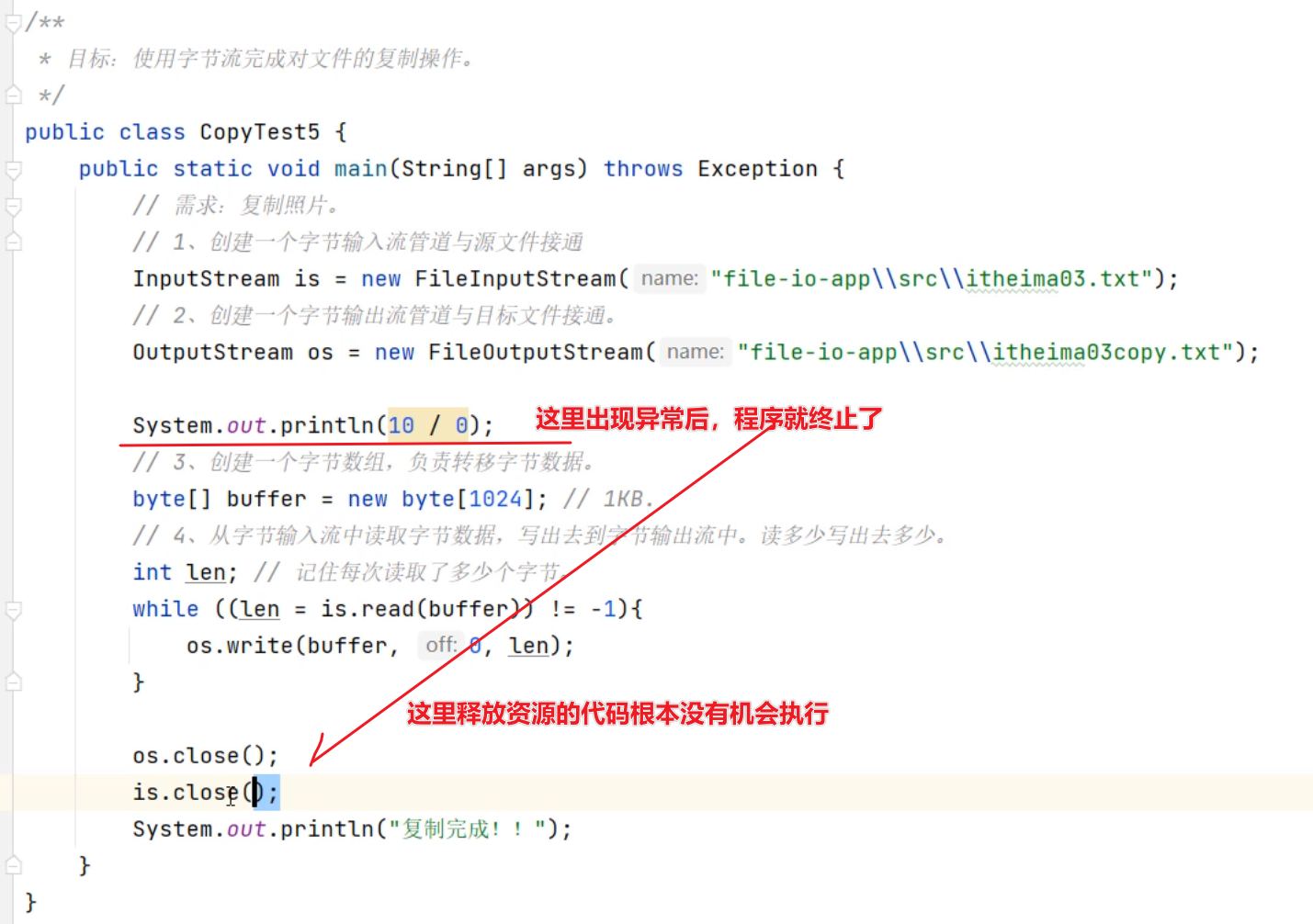
我们现在知道这个问题了,那这个问题怎么解决呢?
在JDK7以前,和JDK7以后分别给出了不同的处理方案。
3.1 JDK7以前的资源释放
在JDK7版本以前,我们可以使用try...catch...finally语句来处理。格式如下
1
2
3
4
5
6
7
8
| try{
}catch(异常类 e){
}finally{
}
|
改造上面的低吗:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| public class Test2 {
public static void main(String[] args) {
InputStream is = null;
OutputStream os = null;
try {
System.out.println(10 / 0);
is = new FileInputStream("file-io-app\\src\\itheima03.txt");
os = new FileOutputStream("file-io-app\\src\\itheima03copy.txt");
System.out.println(10 / 0);
byte[] buffer = new byte[1024];
int len;
while ((len = is.read(buffer)) != -1){
os.write(buffer, 0, len);
}
System.out.println("复制完成!!");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(os != null) os.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(is != null) is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
|
代码写到这里,有很多同学就已经看不下去了。是的,我也看不下去,本来几行代码就写完了的,加上try...catch...finally之后代码多了十几行,而且阅读性并不高。难受....
3.2 JDK7以后的资源释放
刚才很多同学已经发现了try...catch...finally处理异常,并释放资源代码比较繁琐。Java在JDK7版本为我们提供了一种简化的是否资源的操作,它会自动是否资源。代码写起来也想当简单。
格式如下:
1
2
3
4
5
6
7
| try(资源对象1; 资源对象2;){
使用资源的代码
}catch(异常类 e){
处理异常的代码
}
|
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class Test3 {
public static void main(String[] args) {
try (
InputStream is = new FileInputStream("D:/resource/meinv.png");
OutputStream os = new FileOutputStream("C:/data/meinv.png");
){
byte[] buffer = new byte[1024];
int len;
while ((len = is.read(buffer)) != -1){
os.write(buffer, 0, len);
}
System.out.println(conn);
System.out.println("复制完成!!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
day10-IO流(二)
一、字符流
同学们,前面我们学习了字节流,使用字节流可以读取文件中的字节数据。但是如果文件中有中文,使用字节流来读取,就有可能读到半个汉字的情况,这样会导致乱码。虽然使用读取全部字节的方法不会出现乱码,但是如果文件过大又不太合适。
所以Java专门为我们提供了另外一种流,叫字符流,可以字符流是专门为读取文本数据而生的。
1.1 FileReader类
先类学习字符流中的FileReader类,这是字符输入流,用来将文件中的字符数据读取到程序中来。
FileReader读取文件的步骤如下:
1
2
3
| 第一步:创建FileReader对象与要读取的源文件接通
第二步:调用read()方法读取文件中的字符
第三步:调用close()方法关闭流
|

需要用到的方法:先通过构造器创建对象,再通过read方法读取数据(注意:两个read方法的返回值,含义不一样)

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public class FileReaderTest1 {
public static void main(String[] args) {
try (
Reader fr = new FileReader("io-app2\\src\\itheima01.txt");
){
char[] buffer = new char[3];
int len;
while ((len = fr.read(buffer)) != -1){
System.out.print(new String(buffer, 0, len));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
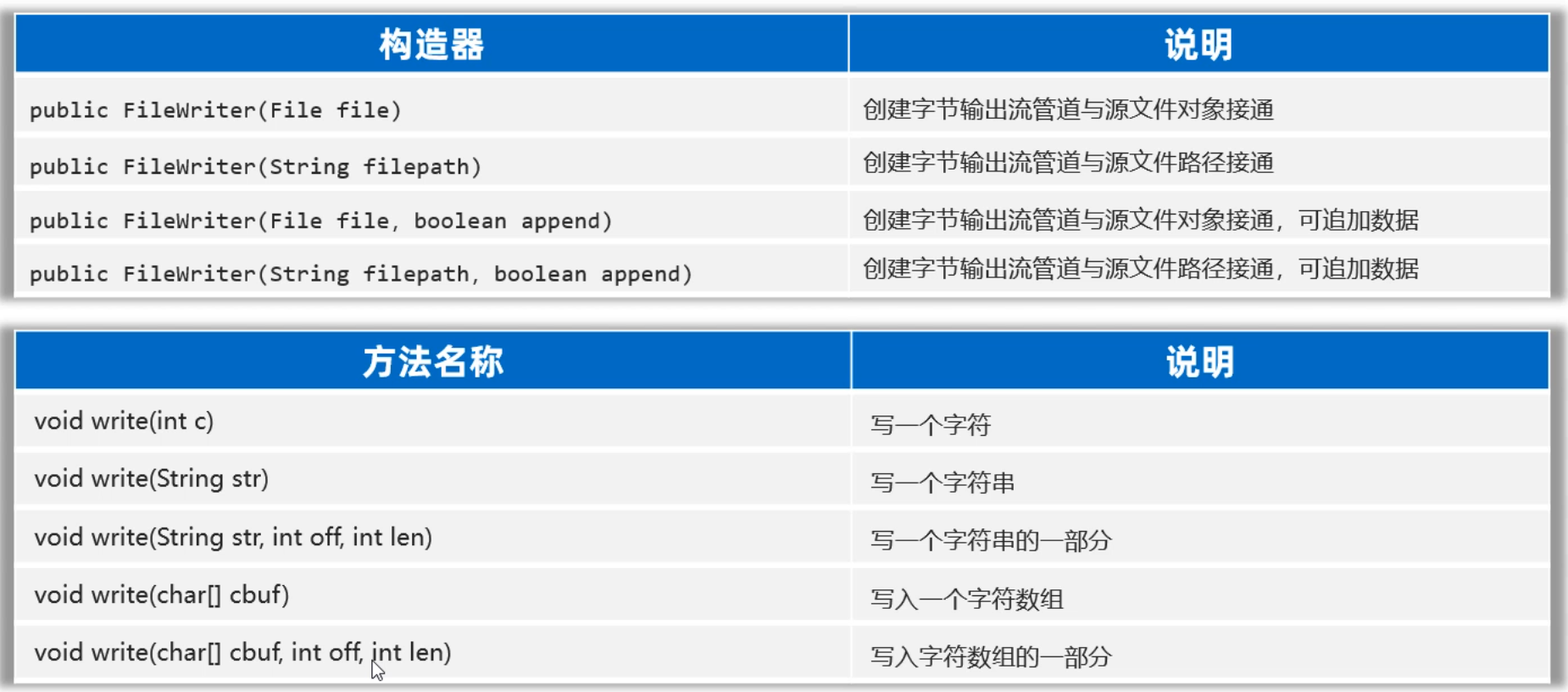
1.2 FileWriter类
在上节课,我们学习了FileReader,它可以将文件中的字符数据读取到程序中来。接下来,我们就要学习FileWriter了,它可以将程序中的字符数据写入文件。
FileWriter往文件中写字符数据的步骤如下:
1
2
3
| 第一步:创建FileWirter对象与要读取的目标文件接通
第二步:调用write(字符数据/字符数组/字符串)方法读取文件中的字符
第三步:调用close()方法关闭流
|
需要用到的方法如下:构造器是用来创建FileWriter对象的,有了对象才能调用write方法写数据到文件。
接下来,用代码演示一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
public class FileWriterTest2 {
public static void main(String[] args) {
try (
Writer fw = new FileWriter("io-app2/src/itheima02out.txt", true);
){
fw.write('a');
fw.write(97);
fw.write("\r\n");
fw.write("我爱你中国abc");
fw.write("\r\n");
fw.write("我爱你中国abc", 0, 5);
fw.write("\r\n");
char[] buffer = {'黑', '马', 'a', 'b', 'c'};
fw.write(buffer);
fw.write("\r\n");
fw.write(buffer, 0, 2);
fw.write("\r\n");
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
1.3 FileWriter写的注意事项
各位同学,刚才我们已经学习了FileWriter字符输出流的基本使用。但是,这里有一个小问题需要和同学们说下一:FileWriter写完数据之后,必须刷新或者关闭,写出去的数据才能生效。
比如:下面的代码只调用了写数据的方法,没有关流的方法。当你打开目标文件时,是看不到任何数据的。
1
2
3
4
5
6
7
|
Writer fw = new FileWriter("io-app2/src/itheima03out.txt");
fw.write('a');
fw.write('b');
fw.write('c');
|
而下面的代码,加上了flush()方法之后,数据就会立即到目标文件中去。
1
2
3
4
5
6
7
8
9
10
|
Writer fw = new FileWriter("io-app2/src/itheima03out.txt");
fw.write('a');
fw.write('b');
fw.write('c');
fw.flush();
|
下面的代码,调用了close()方法,数据也会立即到文件中去。因为close()方法在关闭流之前,会将内存中缓存的数据先刷新到文件,再关流。
1
2
3
4
5
6
7
8
9
10
|
Writer fw = new FileWriter("io-app2/src/itheima03out.txt");
fw.write('a');
fw.write('b');
fw.write('c');
fw.close();
|
但是需要注意的是,关闭流之后,就不能在对流进行操作了。否则会出异常

二、缓冲流
学习完字符流之后,接下来我们学习一下缓冲流。我们还是先来认识一下缓存流,再来说一下它的作用。缓冲流有四种,如下图所示
缓冲流的作用:可以对原始流进行包装,提高原始流读写数据的性能。
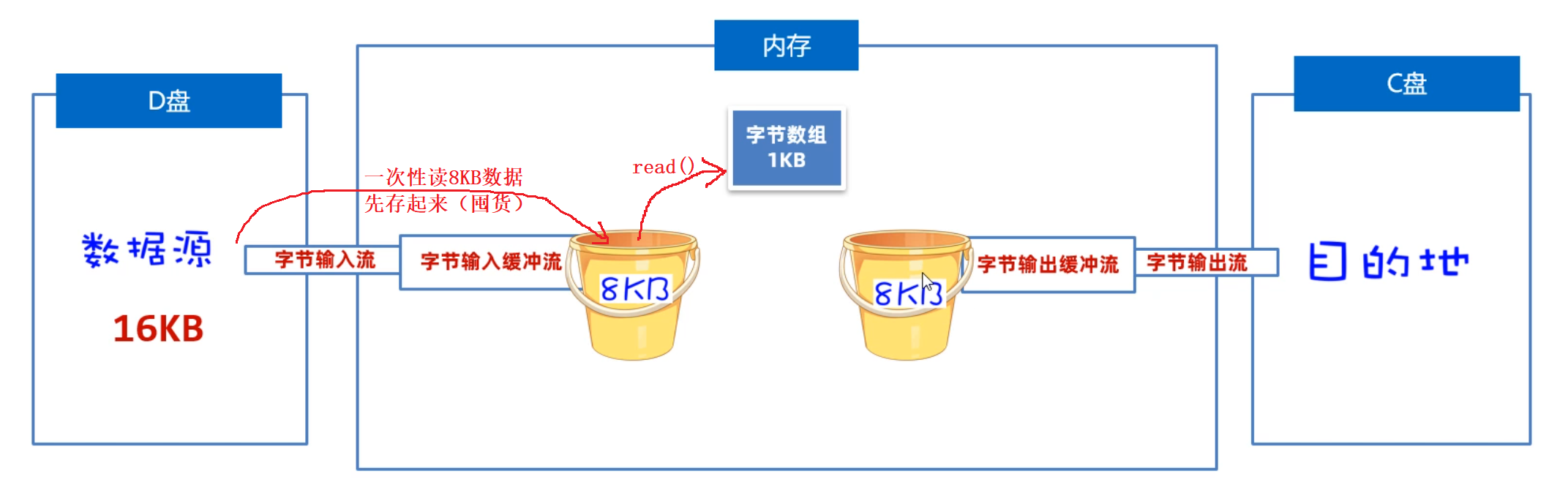
2.1 缓冲字节流
我们先来学习字节缓冲流是如何提高读写数据的性能的,原理如下图所示。是因为在缓冲流的底层自己封装了一个长度为8KB(8129byte)的字节数组,但是缓冲流不能单独使用,它需要依赖于原始流。
- 读数据时:它先用原始字节输入流一次性读取8KB的数据存入缓冲流内部的数组中(ps:
先一次多囤点货),再从8KB的字节数组中读取一个字节或者多个字节(把消耗屯的货)。
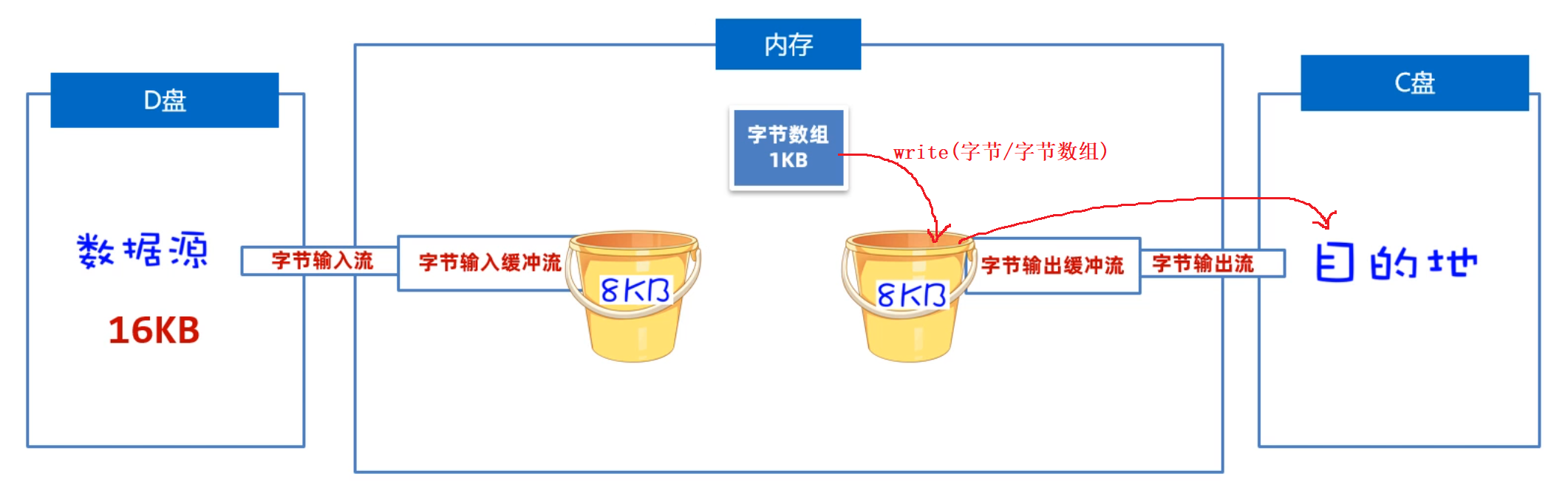
- 写数据时:
它是先把数据写到缓冲流内部的8BK的数组中(ps:
先攒一车货),等数组存满了,再通过原始的字节输出流,一次性写到目标文件中去(把囤好的货,一次性运走)。
在创建缓冲字节流对象时,需要封装一个原始流对象进来。构造方法如下

如果我们用缓冲流复制文件,代码写法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public class BufferedInputStreamTest1 {
public static void main(String[] args) {
try (
InputStream is = new FileInputStream("io-app2/src/itheima01.txt");
InputStream bis = new BufferedInputStream(is);
OutputStream os = new FileOutputStream("io-app2/src/itheima01_bak.txt");
OutputStream bos = new BufferedOutputStream(os);
){
byte[] buffer = new byte[1024];
int len;
while ((len = bis.read(buffer)) != -1){
bos.write(buffer, 0, len);
}
System.out.println("复制完成!!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
2.2 字符缓冲流
接下来,我们学习另外两个缓冲流——字符缓冲流。它的原理和字节缓冲流是类似的,它底层也会有一个8KB的数组,但是这里是字符数组。字符缓冲流也不能单独使用,它需要依赖于原始字符流一起使用。
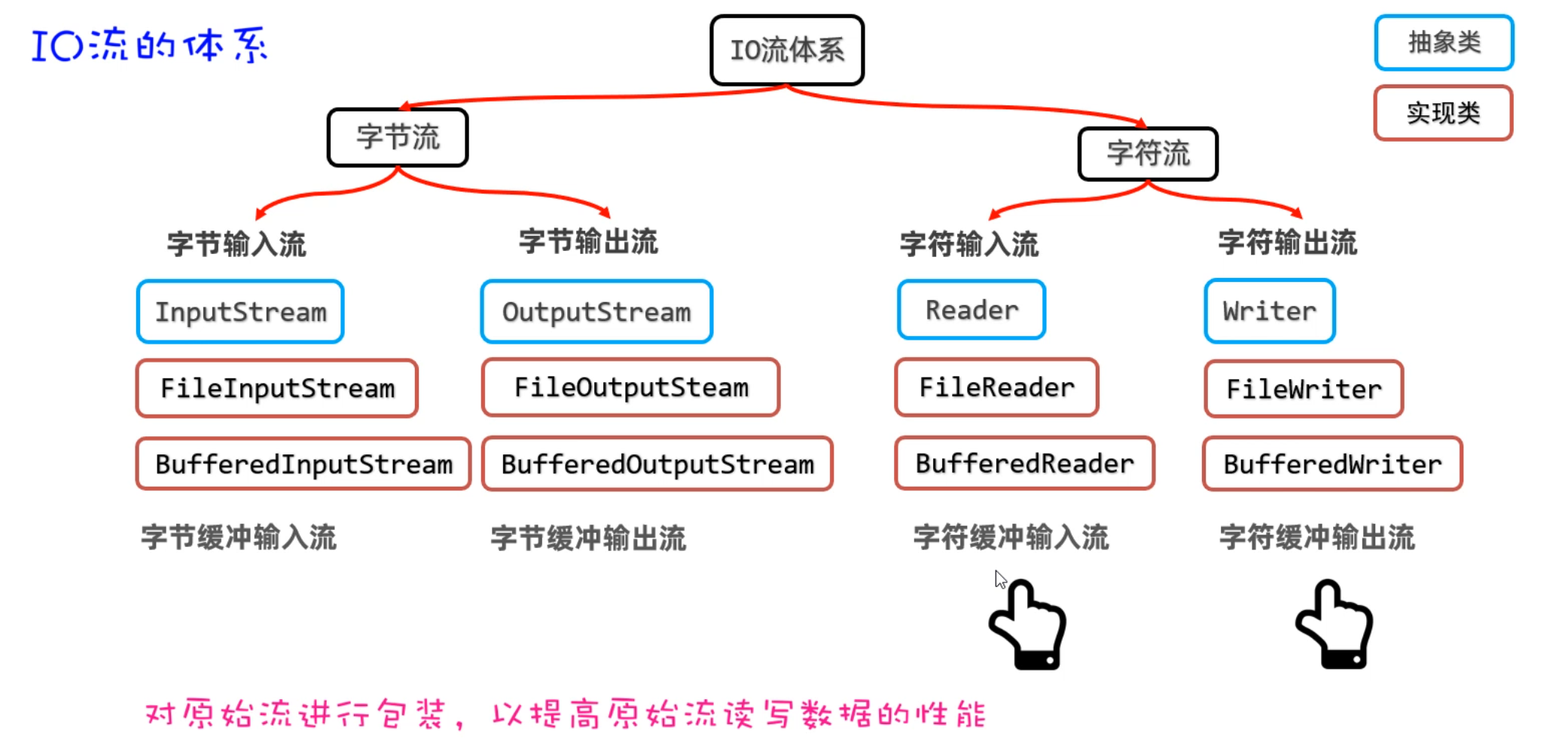
- BufferedReader读数据时:它先原始字符输入流一次性读取8KB的数据存入缓冲流内部的数组中(ps:
先一次多囤点货),再从8KB的字符数组中读取一个字符或者多个字符(把消耗屯的货)。
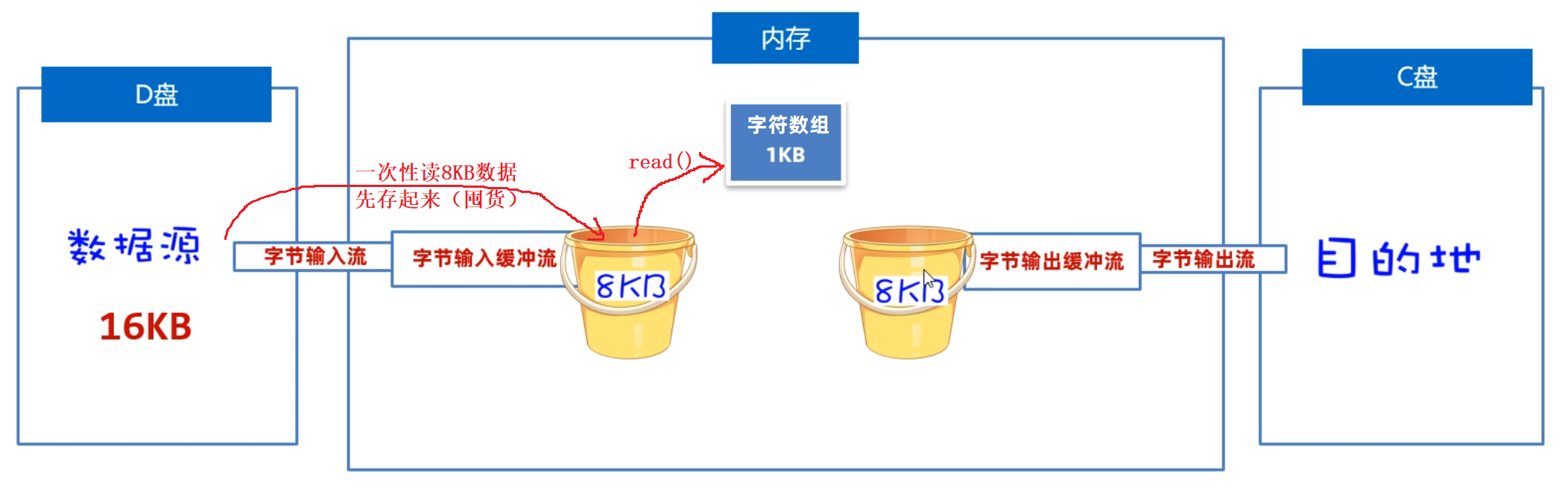
创建BufferedReader对象需要用到BufferedReader的构造方法,内部需要封装一个原始的字符输入流,我们可以传入FileReader.

而且BufferedReader还要特有的方法,一次可以读取文本文件中的一行

使用BufferedReader读取数据的代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| public class BufferedReaderTest2 {
public static void main(String[] args) {
try (
Reader fr = new FileReader("io-app2\\src\\itheima04.txt");
BufferedReader br = new BufferedReader(fr);
){
String line;
while ((line = br.readLine()) != null){
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
- BufferedWriter写数据时:
它是先把数据写到字符缓冲流内部的8BK的数组中(ps:
先攒一车货),等数组存满了,再通过原始的字符输出流,一次性写到目标文件中去(把囤好的货,一次性运走)。如下图所示
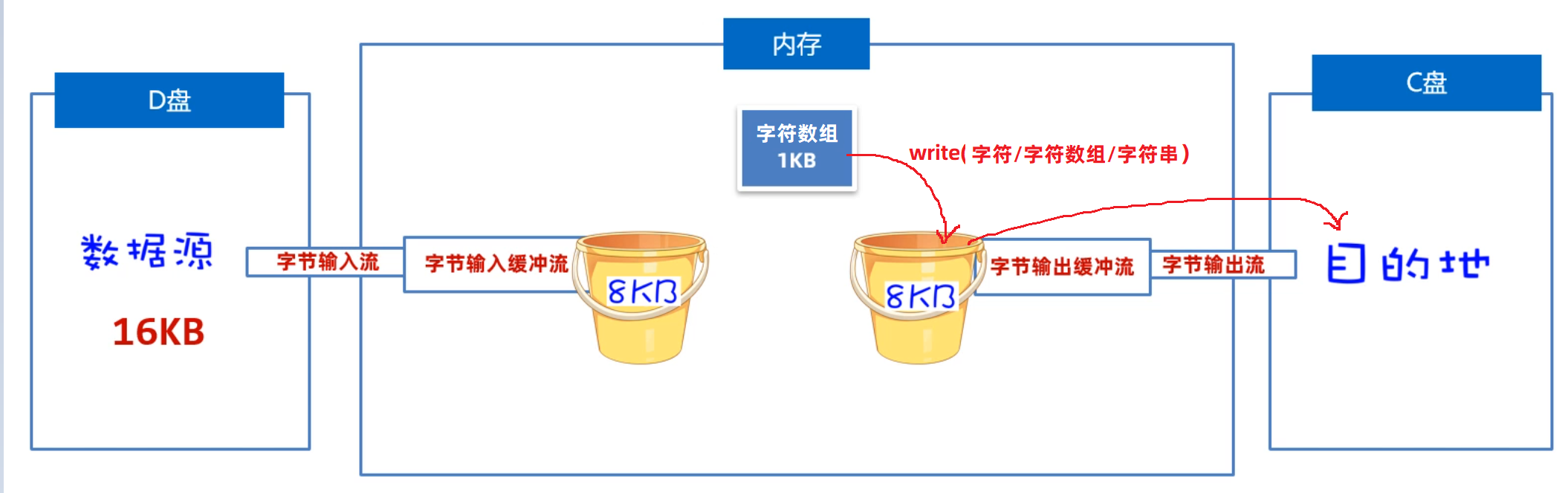
创建BufferedWriter对象时需要用到BufferedWriter的构造方法,而且内部需要封装一个原始的字符输出流,我们这里可以传递FileWriter。

而且BufferedWriter新增了一个功能,可以用来写一个换行符

接下来,用代码演示一下,使用BufferedWriter往文件中写入字符数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class BufferedWriterTest3 {
public static void main(String[] args) {
try (
Writer fw = new FileWriter("io-app2/src/itheima05out.txt", true);
BufferedWriter bw = new BufferedWriter(fw);
){
bw.write('a');
bw.write(97);
bw.write('磊');
bw.newLine();
bw.write("我爱你中国abc");
bw.newLine();
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
2.3 缓冲流性能分析
我们说缓冲流内部多了一个数组,可以提高原始流的读写性能。讲到这一定有同学有这么一个疑问,它和我们使用原始流,自己加一个8BK数组不是一样的吗?
缓冲流就一定能提高性能吗?先告诉同学们答案,缓冲流不一定能提高性能。
下面我们用一个比较大文件(889MB)复制,做性能测试,分别使用下面四种方式来完成文件复制,并记录文件复制的时间。
① 使用低级流一个字节一个字节的复制
② 使用低级流按照字节数组的形式复制
③ 使用缓冲流一个字节一个字节的复制
④ 使用缓冲流按照字节数组的形式复制
1
2
3
4
5
| 低级流一个字节复制: 慢得简直让人无法忍受
低级流按照字节数组复制(数组长度1024): 12.117s
缓冲流一个字节复制: 11.058s
缓冲流按照字节数组复制(数组长度1024): 2.163s
【注意:这里的测试只能做一个参考,和电脑性能也有直接关系】
|
经过上面的测试,我们可以得出一个结论:默认情况下,采用一次复制1024个字节,缓冲流完胜。
但是,缓冲流就一定性能高吗?我们采用一次复制8192个字节试试
1
2
| 低级流按照字节数组复制(数组长度8192): 2.535s
缓冲流按照字节数组复制(数组长度8192): 2.088s
|
经过上面的测试,我们可以得出一个结论:一次读取8192个字节时,低级流和缓冲流性能相当。相差的那几毫秒可以忽略不计。
继续把数组变大,看一看缓冲流就一定性能高吗?现在采用一次读取1024*32个字节数据试试
1
2
| 低级流按照字节数组复制(数组长度8192): 1.128s
缓冲流按照字节数组复制(数组长度8192): 1.133s
|
经过上面的测试,我们可以得出一个结论:数组越大性能越高,低级流和缓冲流性能相当。相差的那几秒可以忽略不计。
继续把数组变大,看一看缓冲流就一定性能高吗?现在采用一次读取1024*6个字节数据试试
1
2
| 低级流按照字节数组复制(数组长度8192): 1.039s
缓冲流按照字节数组复制(数组长度8192): 1.151s
|
此时你会发现,当数组大到一定程度,性能已经提高了多少了,甚至缓冲流的性能还没有低级流高。
最终总结一下:缓冲流的性能不一定比低级流高,其实低级流自己加一个数组,性能其实是不差。只不过缓冲流帮你加了一个相对而言大小比较合理的数组
。
三、转换流
前面我们学习过FileReader读取文件中的字符,但是同学们注意了,FileReader默认只能读取UTF-8编码格式的文件。如果使用FileReader读取GBK格式的文件,可能存在乱码,因为FileReader它遇到汉字默认是按照3个字节来读取的,而GBK格式的文件一个汉字是占2个字节,这样就会导致乱码。
Java给我们提供了另外两种流InputStreamReader,OutputStreamWriter,这两个流我们把它叫做转换流。它们可以将字节流转换为字符流,并且可以指定编码方案。
接下来,我们先学习InputStreamReader类,你看这个类名就比较有意思,前面是InputStream表示字节输入流,后面是Reader表示字符输入流,合在一起意思就是表示可以把InputStream转换为Reader,最终InputStreamReader其实也是Reader的子类,所以也算是字符输入流。
InputStreamReader也是不能单独使用的,它内部需要封装一个InputStream的子类对象,再指定一个编码表,如果不指定编码表,默认会按照UTF-8形式进行转换。
需求:我们可以先准备一个GBK格式的文件,然后使用下面的代码进行读取,看是是否有乱码。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class InputStreamReaderTest2 {
public static void main(String[] args) {
try (
InputStream is = new FileInputStream("io-app2/src/itheima06.txt");
Reader isr = new InputStreamReader(is, "GBK");
BufferedReader br = new BufferedReader(isr);
){
String line;
while ((line = br.readLine()) != null){
System.out.println(line);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
执行完之后,你会发现没有乱码。
3.2 OutputStreamWriter类
接下来,我们先学习OutputStreamWriter类,你看这个类名也比较有意思,前面是OutputStream表示字节输出流,后面是Writer表示字符输出流,合在一起意思就是表示可以把OutputStream转换为Writer,最终OutputStreamWriter其实也是Writer的子类,所以也算是字符输出流。
OutputStreamReader也是不能单独使用的,它内部需要封装一个OutputStream的子类对象,再指定一个编码表,如果不指定编码表,默认会按照UTF-8形式进行转换。
需求:我们可以先准备一个GBK格式的文件,使用下面代码往文件中写字符数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class OutputStreamWriterTest3 {
public static void main(String[] args) {
try (
OutputStream os = new FileOutputStream("io-app2/src/itheima07out.txt");
Writer osw = new OutputStreamWriter(os, "GBK");
BufferedWriter bw = new BufferedWriter(osw);
){
bw.write("我是中国人abc");
bw.write("我爱你中国123");
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
四、打印流
接下来,我们学习打印流,其实打印流我们从开学第一天就一直再使用,只是没有学到你感受不到而已。打印流可以实现更加方便,更加高效的写数据的方式。
4.1 打印流基本使用
打印流,这里所说的打印其实就是写数据的意思,它和普通的write方法写数据还不太一样,一般会使用打印流特有的方法叫print(数据)或者println(数据),它打印啥就输出啥。
打印流有两个,一个是字节打印流PrintStream,一个是字符打印流PrintWriter,如下图所示
PrintStream和PrintWriter的用法是一样的,所以这里就一块演示了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public class PrintTest1 {
public static void main(String[] args) {
try (
PrintWriter ps =
new PrintWriter(new FileOutputStream("io-app2/src/itheima08.txt", true));
){
ps.print(97);
ps.print('a');
ps.println("我爱你中国abc");
ps.println(true);
ps.println(99.5);
ps.write(97);
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
4.2 重定向输出语句
其实我们开学第一课,就给同学们讲过System.out.println()这句话表示打印输出,但是至于为什么能够输出,其实我们一直不清楚。
以前是因为知识储备还不够,无法解释,到现在就可以给同学们揭晓谜底了,因为System里面有一个静态变量叫out,out的数据类型就是PrintStream,它就是一个打印流,而且这个打印流的默认输出目的地是控制台,所以我们调用System.out.pirnln()就可以往控制台打印输出任意类型的数据,而且打印啥就输出啥。
而且System还提供了一个方法,可以修改底层的打印流,这样我们就可以重定向打印语句的输出目的地了。我们玩一下,
直接上代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class PrintTest2 {
public static void main(String[] args) {
System.out.println("老骥伏枥");
System.out.println("志在千里");
try ( PrintStream ps = new PrintStream("io-app2/src/itheima09.txt"); ){
System.setOut(ps);
System.out.println("烈士暮年");
System.out.println("壮心不已");
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
此时打印语句,将往文件中打印数据,而不在控制台。
五、数据流
同学们,接下我们再学习一种流,这种流在开发中偶尔也会用到。比如,我们想把数据和数据的类型一并写到文件中去,读取的时候也将数据和数据类型一并读出来。这就可以用到数据流,有两个DataInputStream和DataOutputStream.
5.1 DataOutputStream类
我们先学习DataOutputStream类,它也是一种包装流,创建DataOutputStream对象时,底层需要依赖于一个原始的OutputStream流对象。然后调用它的wirteXxx方法,写的是特定类型的数据。

代码如下:往文件中写整数、小数、布尔类型数据、字符串数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class DataOutputStreamTest1 {
public static void main(String[] args) {
try (
DataOutputStream dos =
new DataOutputStream(new FileOutputStream("io-app2/src/itheima10out.txt"));
){
dos.writeInt(97);
dos.writeDouble(99.5);
dos.writeBoolean(true);
dos.writeUTF("黑马程序员666!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
学习完DataOutputStream后,再学习DataIntputStream类,它也是一种包装流,创建DataInputStream对象时,底层需要依赖于一个原始的InputStream流对象。然后调用它的readXxx()方法就可以读取特定类型的数据。

代码如下:读取文件中特定类型的数据(整数、小数、字符串等)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class DataInputStreamTest2 {
public static void main(String[] args) {
try (
DataInputStream dis =
new DataInputStream(new FileInputStream("io-app2/src/itheima10out.txt"));
){
int i = dis.readInt();
System.out.println(i);
double d = dis.readDouble();
System.out.println(d);
boolean b = dis.readBoolean();
System.out.println(b);
String rs = dis.readUTF();
System.out.println(rs);
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
六、序列化流
各位同学同学,还有最后一个流要学习,叫做序列化流。序列化流是干什么用的呢?
我们知道字节流是以字节为单位来读写数据、字符流是按照字符为单位来读写数据、而对象流是以对象为单位来读写数据。也就是把对象当做一个整体,可以写一个对象到文件,也可以从文件中把对象读取出来。
这里有一个新词
序列化,第一次听同学们可能还比较陌生,我来给同学们解释一下
1
2
| 序列化:意思就是把对象写到文件或者网络中去。(简单记:写对象)
反序列化:意思就是把对象从文件或者网络中读取出来。(简单记:读对象)
|
6.1 ObjectOutputStraem类
接下来,先学习ObjectOutputStream流,它也是一个包装流,不能单独使用,需要结合原始的字节输出流使用。
代码如下:将一个User对象写到文件中去
- 第一步:先准备一个User类,必须让其实现Serializable接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public class User implements Serializable {
private String loginName;
private String userName;
private int age;
private transient String passWord;
public User() {
}
public User(String loginName, String userName, int age, String passWord) {
this.loginName = loginName;
this.userName = userName;
this.age = age;
this.passWord = passWord;
}
@Override
public String toString() {
return "User{" +
"loginName='" + loginName + '\'' +
", userName='" + userName + '\'' +
", age=" + age +
", passWord='" + passWord + '\'' +
'}';
}
}
|
- 第二步:再创建ObjectOutputStream流对象,调用writeObject方法对象到文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class Test1ObjectOutputStream {
public static void main(String[] args) {
try (
ObjectOutputStream oos =
new ObjectOutputStream(new FileOutputStream("io-app2/src/itheima11out.txt"));
){
User u = new User("admin", "张三", 32, "666888xyz");
oos.writeObject(u);
System.out.println("序列化对象成功!!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
注意:写到文件中的对象,是不能用记事本打开看的。因为对象本身就不是文本数据,打开是乱码

怎样才能读懂文件中的对象是什么呢?这里必须用反序列化,自己写代码读。
接下来,学习ObjectInputStream流,它也是一个包装流,不能单独使用,需要结合原始的字节输入流使用。
接着前面的案例,文件中已经有一个Student对象,现在要使用ObjectInputStream读取出来。称之为反序列化。
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class Test2ObjectInputStream {
public static void main(String[] args) {
try (
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("io-app2/src/itheima11out.txt"));
){
User u = (User) ois.readObject();
System.out.println(u);
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
七、补充知识:IO框架
最后,再给同学们补充讲解一个知识,叫做IO框架。它有什么用呢?有同学经常问老师,我们只学习了IO流对文件复制,能不能复制文件夹呀?
当然是可以咯,但是如果让我们自己写复制文件夹的代码需要用到递归,还是比较麻烦的。为了简化对IO操作,由apache开源基金组织提供了一组有关IO流小框架,可以提高IO流的开发效率。
这个框架的名字叫commons-io:其本质是别人写好的一些字节码文件(class文件),打包成了一个jar包。我们只需要把jar包引入到我们的项目中,就可以直接用了。
这里给同学们介绍一个jar包中提供的工具类叫FileUtils,它的部分功能如下,很方便,你一看名字就知道怎么用了。

在写代码之前,先需要引入jar包,具体步骤如下
1
2
3
| 1.在模块的目录下,新建一个lib文件夹
2.把jar包复制粘贴到lib文件夹下
3.选择lib下的jar包,右键点击Add As Library,然后就可以用了。
|
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class CommonsIOTest1 {
public static void main(String[] args) throws Exception {
FileUtils.copyFile(new File("io-app2\\src\\itheima01.txt"), new File("io-app2/src/a.txt"));
FileUtils.copyDirectory(new File("D:\\resource\\私人珍藏"), new File("D:\\resource\\私人珍藏3"));
FileUtils.deleteDirectory(new File("D:\\resource\\私人珍藏3"));
Files.copy(Path.of("io-app2\\src\\itheima01.txt"), Path.of("io-app2\\src\\b.txt"));
System.out.println(Files.readString(Path.of("io-app2\\src\\itheima01.txt")));
}
}
|


 wechat
wechat alipay
alipay

